Honeybee (Kakao MLLM) Inference 테스트
Honeybee Inference Test
MLLM 및 honeybee란
- MLLM
MLLM(Multimodal Large Language Model)은 다양한 modality의 데이터를 처리할 수 있다.
쉽게 말하면 기존의 GPT3.5를 예시로 들면 text를 input으로 받아서 그에 대한 답변을 text로 생성하지만 최근 GPT-4의 경우 DALL-E 3를 이용해 특정한 이미지를 생성할 수도 있고, 이미지를 첨부하여 그에 대한 해석도 가능하다.
최근 떠오르는 LLM 분야에서도 특히 각광받는 분야가 MLLM 분야이다. - Honeybee
MLLM의 경우 실제 학습시키는 코드를 제공하는 경우는 찾아보기 힘든데 이번에 카카오브레인에서 honeybee라는 MLLM을 만들면서 소스 코드를 오픈소스로 공개하였다.
글 작성 기준으로 train하는 코드가 업데이트되어있지는 않지만 가까운 시일 내에 업데이트 예정이라고 한다.
환경 설정 및 준비
-
Python 버전
또한 공식 문서의 파이썬 코드 중 일부는 python의 type hint를 사용하고 있는데 특정 문법은 python 3.10이상에서 지원한다.
따라서 문제가 될 수 있는 type hint 부분을 수정하거나 3.10이상의 파이썬 환경에서 구동하도록 한다. -
PyTorch 버전
공식 Github에서는 pytorch 2.0.1을 권장하고 있다.
본인의 CUDA 버전에 맞게 설치하고 CUDA 버전 및 Nvidia-Driver 버전이 너무 낮다면 업데이트를 하는 게 다른 패키지 및 버전 문제로 인한 오류를 피할 수 있다. -
소스 코드 클론 및 라이브러리 설치
공식 Github를 참고하자.1
git clone https://github.com/kakaobrain/honeybee.git
기본적으로는 requirements.txt의 라이브러리를 설치하고 Gradio를 통한 demo를 이용해보고 싶다면 requirements_demo.txt의 라이브러리까지 설치한다.
1
2
3
4
pip install -r requirements.txt
# additional requirements for demo
pip install -r requirements_demo.txt
- SentencePiece
추가적으로 이 모델을 실행하려면 sentencepiece라이브러리가 필요하다.
혹시라도 다른 LLM 모델을 실험하면서 설치한 경험이 있다면 간단하게1
pip install sentencepiece로 설치할 수 있다.
만약 처음이라면 SentencePiece Github를 참고하자. 우분투 기준으로 아래의 명령어1
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
1
2
3
4
5
6
7
8
git clone https://github.com/google/sentencepiece.git
cd sentencepiece
mkdir build
cd build
cmake ..
make -j $(nproc)
sudo make install
sudo ldconfig -v
를 순차적으로 입력하여 빌드하면 pip를 이용하여 sentencepiece를 설치할 수 있다.
모델 다운로드
Model Zoo 파트에 여러 학습된 모델들이 제공되어 있다.
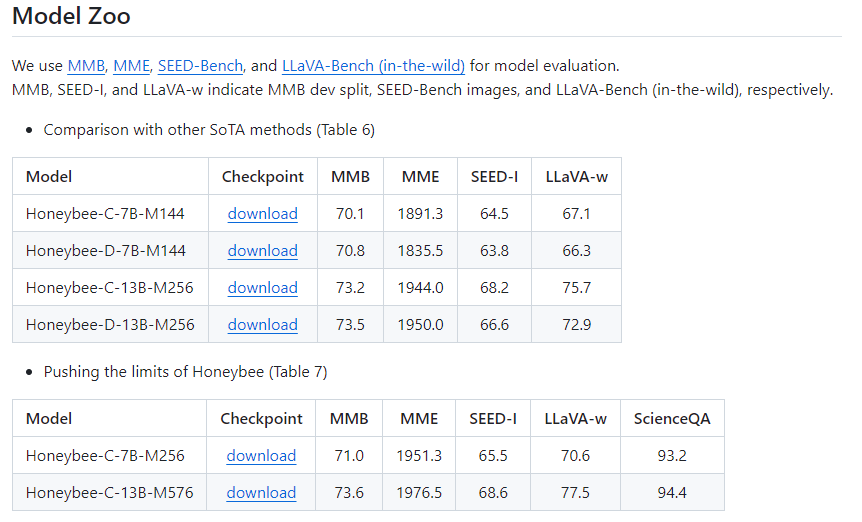
각 모델은 용량이 10GB이상으로 무겁다.
honeybee의 하위폴더에 weight라는 폴더를 만들어 거기에 다운받기로 하자.(압축은 풀어야함)
inference_example.ipynb의 flow에 따르면 checkpoints라는 폴더를 만들어 그 안에 모델을 저장해야 하지만
주피터 환경에서 실행하고자한다면 checkpoints라는 폴더명은 충돌이 일어날 수 있다.
Inference test
inference_example.ipynb를 실행하자. 각 셀을 순차적으로 실행하면 되지만 세 번째 셀의 내용을 아까 다운로드받은 모델의 경로로 맞춰준다.
1
2
3
4
ckpt_path = "weights/7B-C-Abs-M144/last"
model, tokenizer, processor = get_model(ckpt_path, use_bf16=True)
model.cuda()
print("Model initialization is done.")
네 번째 셀의 내용은 프롬프트와 이미지 경로이다.
1
2
prompts = [construct_input_prompt("Please read all texts in image")]
image_list = ["./examples/ocr1.png"]
프롬프트에는 질문할 내용을 적는다.
다섯 번째 셀의 내용은 HuggingFace의 Transformers 라이브러리에서 제공하는 generate 메서드의 인자들이다.
- do_sample: True로 설정하면, 모델이 확률 분포를 기반으로 텍스트를 샘플링하여 생성하고 False이면, 모델은 가장 높은 확률을 가진 토큰을 선택하여 생성한다.
- top_k: 토큰 분포에서 선택 가능한 토큰의 최대 개수를 지정한다. top_k 값을 높이면 더 다양한 텍스트를 생성할 수 있지만, 불안정할 수 있다.
- max_length: 생성되는 텍스트의 최대 길이를 제한하며 초과하는 경우 텍스트가 잘린다.
임의로 변경할 수 있고 변경해보면서 실험해 보는 것도 좋다.
나머지 셀을 순차적으로 실행하면 마지막 셀에 원본 이미지와 결과가 나온다.
1
prompts = [construct_input_prompt("Explain why this meme is funny.")]
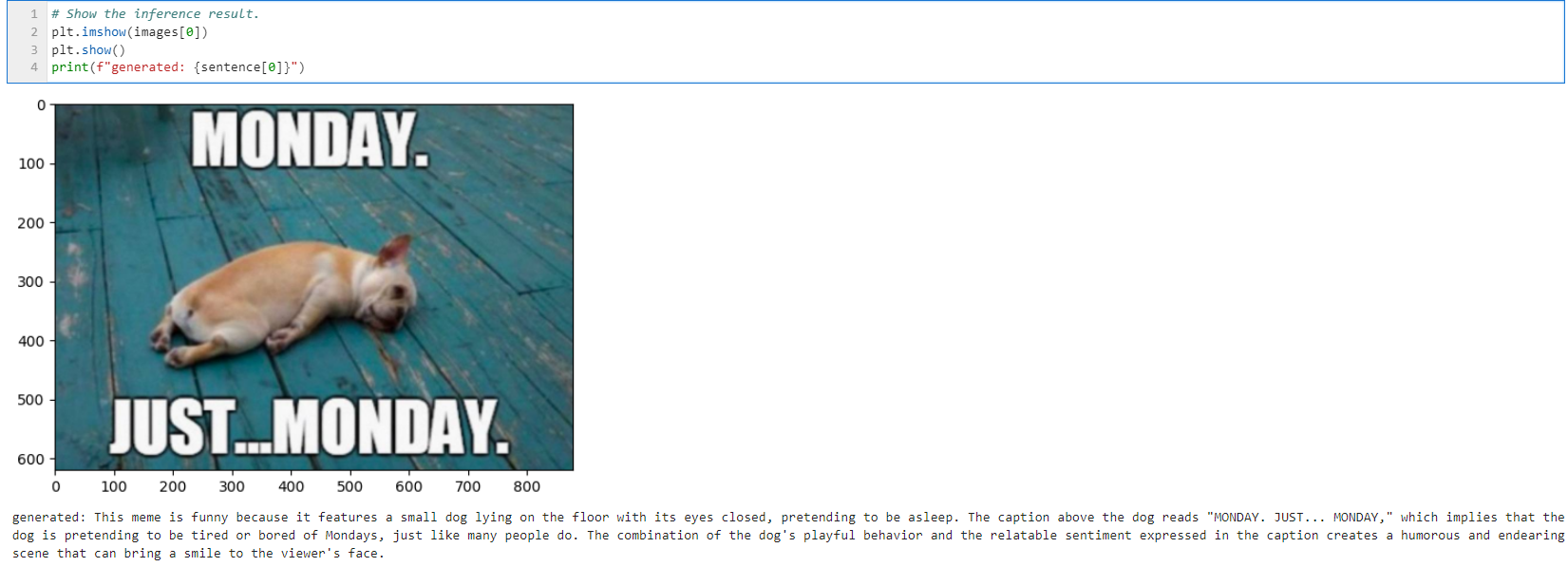
기본으로 제공하는 예제이다.
1
prompts = [construct_input_prompt("Please read all texts in image")]
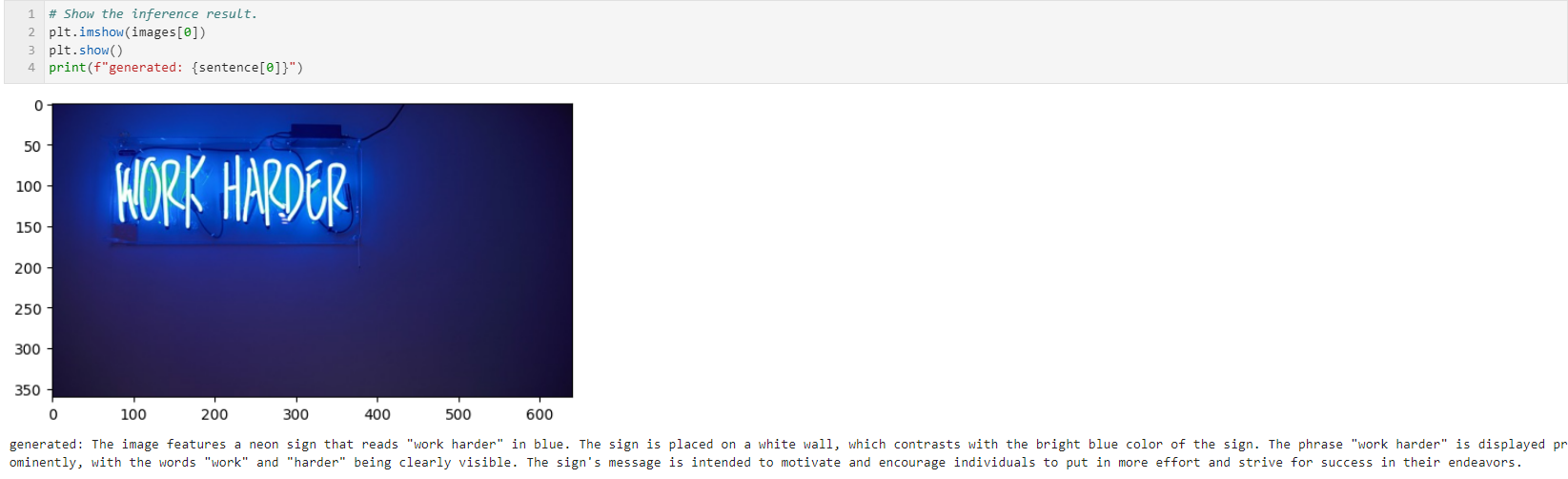
OCR도 어느정도 가능한 것으로 보인다.
다른 이미지로도 실험해 보았는데, 글자가 작은 경우 인식 성능이 떨어진다.
1
prompts = [construct_input_prompt("Among the two images, one has a defect. Where is the scratch when the image is divided into 2x2 parts?")]
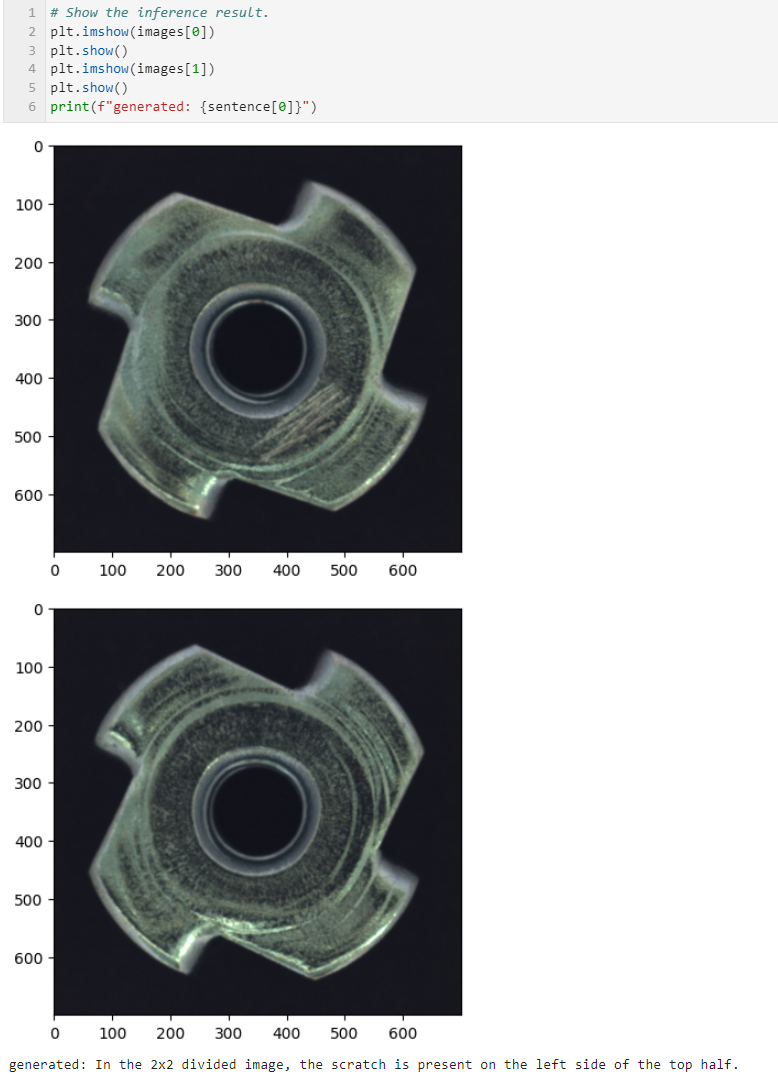
두 개의 이미지를 넣을 수도 있다. 하지만 질문에 제대로 대답하지 못하였다.
1
prompts = [construct_input_prompt("Explain this image.")]
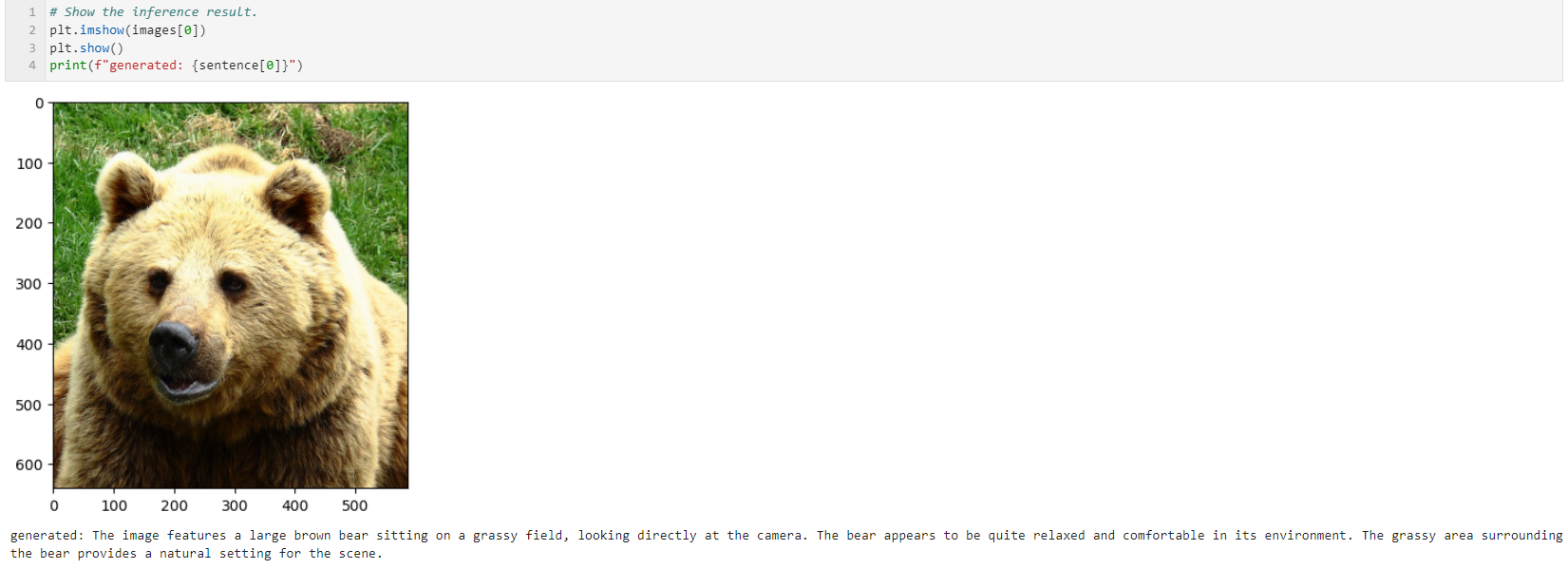
제공한 이미지가 곰인 것도 식별한다.
결론
다른 MLLM과 같이 hallucination은 심하지만 생각 이상으로 이미지에 대한 여러 질문들을 잘 답변하는 것으로 보인다.
한국어로 질문했을 때에는 시간도 더 걸리고 성능도 떨어지는 것으로 보인다.
기술의 발전을 위해 오픈 소스로 공개한 것에 대해 감사하게 생각한다.
댓글남기기