Segment Anything (01) - 논문 리뷰
arXiv 2023. [Paper] [Page] [Github]
Kirillov, Alexander, et al.
Meta AI Research, FAIR
5 Apr 2023
Introduction
Segment Anything 논문 리뷰를 진행하고자 한다. Meta AI 에서 발표한 segmentation에 대한 대규모 프로젝트에 해당하는 논문이다.
도입부에서 논문은 다음과 같이 시작한다.
웹 규모 데이터셋에서 pretrain된 LLM은 강력한 zero-shot & few-shot 일반화로 NLP를 혁신중이다. 이러한 foundation model들은 훈련 중에 본적이 없는 작업 및 데이터 분포에 대한 일반화 능력을 갖추고 있다. 이런 능력은 보통 수작업으로 만든 텍스트를 사용하여 언어 모델에 유효한 텍스트 응답을 생성하도록 유도하는 프롬프로 엔지니어링을 통해 구현된다. 웹에서 풍부한 텍스트 corpus(말뭉치)로 확장 및 훈련된 경우, 이러한 모델의 zero/few-shot 성능은 놀랍게도 fine-tuning된 모델과 잘 비교된다. 경험적으로 모델 크기, 데이터셋 크기, 학습 계산량을 통해 개선되는 추세이다.
정도는 조금 덜하나 컴퓨터 비전 분야에서도 foundation model에 관한 연구가 이루어졌다. 아마 가장 유명한 예시는 paired 텍스트와 이미지를 매칭시키는 것이다. 예를 들어 CLIP과 ALIGN은 두 modality를 align하는 텍스트 및 이미지 인코더를 학습시키기 위해 contrastive learning(대조학습)을 이용한다. 학습 이후에는 엔지니어링된 텍스트 프롬프트를 통해 새로운 시각적 개념과 데이터 분포에 대한 zero-shot 일반화가 가능해진다. 이러한 인코더는 다른 모듈과 효과적으로 결합하여 하위작업 (ex. 이미지 생성, DALLE)을 가능하게 한다. 비전 및 언어 인코더에 대한 많은 진전이 있었으나 컴퓨터 비전에는 이를 넘어선 다양한 문제가 있으며 이 중 많은 문제들에 대한 풍부한 훈련 데이터가 존재하지 않는다.
본 논문의 목표는 image segmentation을 위한 foundation model의 구축이다. 즉 프롬프트가 가능한 모델을 개발하고 광범위 데이터셋에서 사전학습시키려고 한다. 이 모델로 강력한 일반화를 가능하게 하는 task를 사용하여 프롬프트 엔지니어링을 통해 여러 다양한 하위 segmentation 문제를 해결하고자 한다.
이 계획의 성공은 task, 모델, 데이터 3가지 요소에 달려 있다. 이들을 개발하기 위해 다음과 같은 질문을 다룬다.
- 어떤 task가 zero-shot 일반화를 가능하게 하는가?
- 해당 모델 아키텍쳐는 무엇인가?
- 이 작업과 모델을 지원할 수 있는 데이터는 무엇인가?
이러한 질문은 서로 얽혀 있어 포괄적인 해결책이 필요하다. 먼저 강력한 사전학습 목적을 제공하고 다양한 하위 어플리케이션을 충분히 가능하게 할 promptable segmentation task를 정의하는 것으로 시작한다. 이 task에는 프롬프트에 의해 실시간으로 segmentation mask를 출력할 수 있는 모델이 필요하다. 모델을 학습시키기 위해서는 대규모 데이터 소스가 필요하나 불행히도 segmentation을 위한 웹 규모 데이터 소스가 존재하지 않는다. 따라서 이를 해결하기 위해 “data engine”을 구축한다. 효율적인 모델을 사용하여 데이터 수집을 돕고 새롭게 수집된 데이터를 사용하여 모델을 개선하는 과정을 반복한다.
간단하게 설명하자면 저자들은 LLM의 foundation model의 일반화 성능에 영감을 받고 이러한 task를 segmentation에 적용해 보자!라고 생각한다. 특정한 입력이 들어가면 segmentation 마스크를 반환하는 모델이 필요하다. 모델 학습하려고 보니 mask에 대한 데이터가 부족하네? 이미지 구한 다음에 라벨링하고 모델학습하고 모델이 라벨링하고 수정하고를 반복해서 데이터셋 구축했다. 이런 느낌으로 보면 될 것 같다.
Task
NLP에서 foundation model들은 새로운 데이터셋에 대해서도 “prompting” 기법을 통해 zero/few-shot learning이 가능하다. 여기에서 영감을 얻어 어떠한 segmenation에 관한 프롬프트가 주어지면 유효한 segmentation mask를 반환할 수 있는 promptable segmentation task를 제안한다.
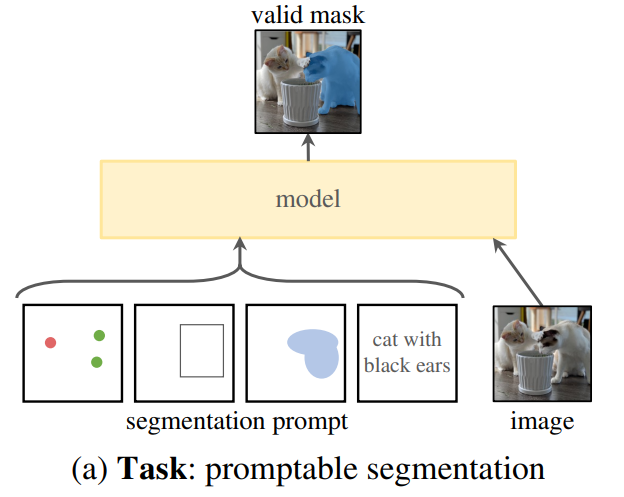
그림에서 볼 수 있듯이 segmentation을 수행할 공간 혹은 text 정보가 될 수 있다.
Model
프롬프트 가능한 segmentation task 와 real-world 적용은 모델 아키텍쳐에 제약을 가한다. 특히 모델은 유연한 프롬프트를 지원해야 하고 대화형 사용을 위해 실시간으로 마스크를 계산해야 하며 ambiguity-aware해야 한다. 저자들은 단순한 디자인이 이 3가지 제약 조건을 모두 충족한다고 한다:
- 강력한 이미지 인코더가 이미지 임베딩을 계산한다.
- 프롬프트 인코더가 프롬프트를 임베딩한다음 두 정보 소스를 가벼운 마스크 디코더에 결합하여 segmentation 마스크를 예측한다. 이 모델을 Segment Anything Model, SAM이라 부른다.(그림)
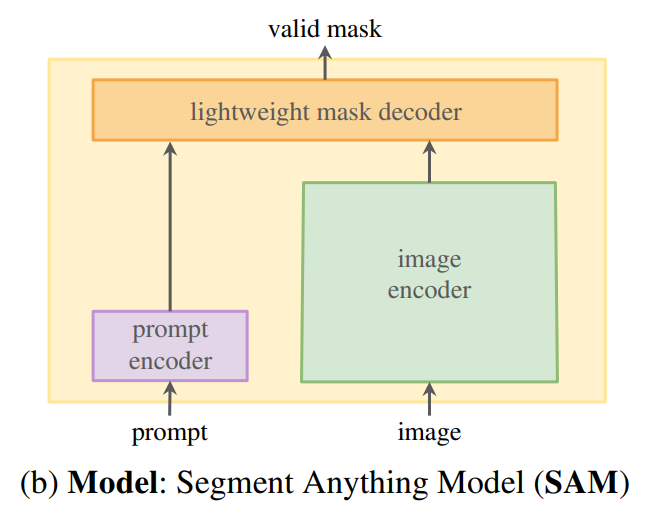
SAM을 이미지 인코더와 빠른 프롬프트 인코더/마스크 인코더로 분리함으로써, 동일한 이미지 임베딩을 다른 프롬프로 재사용할 수 있다. 이미지 임베딩이 주어지면 프롬프트 인코더와 마스크 인코더는 웹 브라우저에서 50ms 이내에 프롬프트에서 마스크를 예측한다. 포인트, 박스, 마스크 프롬프트에 중점을 두고 있으며 SAM이 amiguity-aware하게 만들기 위해 하나의 프롬프트에 대해 여러 마스크를 예측하도록 설계한다.
Data
새로운 데이터 분포에 대한 강력한 일반화 성능을 달성을 위해서는 기존 segmentation dataset을 넘어서는 다양한 set에 대한 학습이 필요하다. 데이터를 얻을수는 있으나 mask에 대한 데이터는 풍부하지 않다. 저자들은 해결책으로 “data engine”이라는 것을 구축한다.
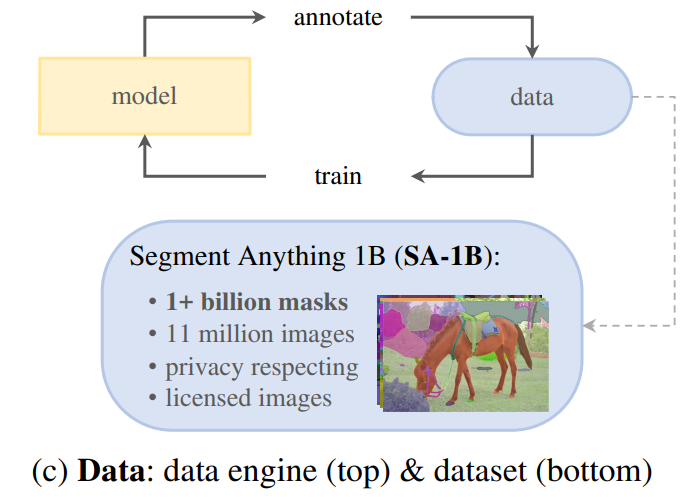
데이터 엔진은 assisted-manual, semi-automatic, fully-automatic의 3단계로 구성된다. 논문에 설명이 살짝 모호하게 되어 있는데 먼저 작업자가 수동으로 라벨링하고, SAM이 mask 자동으로 생성하고 작업자가 나머지 객체 라벨링하고를 반복하는 식이다. “brush”나 “eraser”와 같은 편집 기능이 있는 툴을 사용해서 라벨링했다고 한다. 이미지는 평균적으로 $3300 \times 4950$의 고해상도 이미지이다. 배포용으로는 짧은 쪽의 길이를 1500픽셀로 설정하여 다운샘플링하여 공개하고 있다고 한다. 또한 정보 보호를 위해 얼굴 및 차량 보호판은 블러처리되어 공개하고 있다.
Dataset
최종 데이터셋은 SA-1B이며 11M 개의 licensed 및 개인정보 보호 이미지에서 추출한 10억 개 이상의 마스크를 포함한다.

Release
데이터셋을 Apache 2.0 라이센스로 제공한다.
온라인 데모 역시 제공한다.
Segment Anything Task
저자들은 다음 토큰 예측 task가 foundation model의 사전학습에 이용되고 프롬프트 엔지니어링을 통해 다양한 하위 task를 해결하는 NLP에서 영감을 얻는다. Segmentation을 위한 foundation model의 구축을 위해 유사한 task를 정의하는 것을 목표로 한다.
Task
NLP의 프롬프트의 개념을 segmentation으로 변환한다. 여기에서 프롬프트는 전경/배경 포인트, 박스, 마스크, 자유 형식 텍스트 등등이 될 수 있다. Promptable segmentation task는 이러한 프롬트트가 주어지면 유효한 마스크를 생성하는 것이다. “유효한” 마스크의 요건은 프롬프트가 모호하더라도 적어도 하나에 대해 합리적인 마스크여야 한다. 그림을 보면 동일한 포인트 프롬프트로부터 생성된 유효한 마스크들이 나타나 있다.

서로 다른 마스크를 생성했지만 합리적으로 생성했음을 볼 수 있다. 이는 모호한 프롬프트에 대해 일관된 응답을 출력하는 언어 모델을 기대하는 것과 유사하다. 이 task를 선택하는 것은 자연스로운 사전학습 알고리즘과 프롬프팅을 통해 하위 task로의 zero-shot transfer를 위한 일반적 방법으로 이어지기 때문이다.
Pre-training
프롬프트 가능한 segmentation task는 각 학습 샘플에 대한 일련의 프롬프트(점, 박스, 마스크)를 시뮬레이션하고 모델의 마스크 예측을 정답(ground truth)와 비교하는 자연스러운 사전학습 알고리즘을 제안한다. 프롬프트가 모호한 경우에도 항상 유용한 마스크를 예측하는 것이 목표이다. 이는 사전 학습된 모델이 모호성을 포함한 사용 예시에서 효과적임을 보장한다. 이 task를 잘 수행하는 것은 어렵고 전문적인 모델링 및 loss의 선택이 필요하다.
Zero-shot transfer
직관적으로, 본 논문의 사전 학습 작업은 추론 시점에 어떠한 프롬프트에도 적절히 대응할 수 있는 능력을 부여한다고 주장한다. 따라서 하위 작업은 적절한 프롬프트를 엔지니어링하여 해결할 수 있다고 한다. 예를 들어 고양이에 대한 instance segmentation은 detector의 박스 출력을 모델에 프롬프트로 제공함으로써 해결할 수 있다.
Related task
Segmentation은 다양한 분야로 구성된다: interactive segmentation, edge detection, super pixelization, object proposal generation, foreground segmentation, semantic segmentation, instance segmentation, panoptic segmentation 등등. 본 논문의 프롬프트 가능한 segmentation 작업의 목표는 프롬프트 엔지니어링을 통해 기존 및 새로운 segmentation 작업에 적용할 수 있는 모델을 생성하는 것을 목표로 한다. 중요한 차이점은 promptable segmentation을 위해 학습된 모델이 추론할 때 다른 작업을 수행할 수 있다는 것이다. 예를 들어 promptable segmentation model이 기존의 object detector와 instance segmentation을 수행할 수 있다.
Segment Anything Model
SAM은 그림과 같이 이미지 인코더, 프롬프트 인코더, 마스크 디코더로 구성된다.
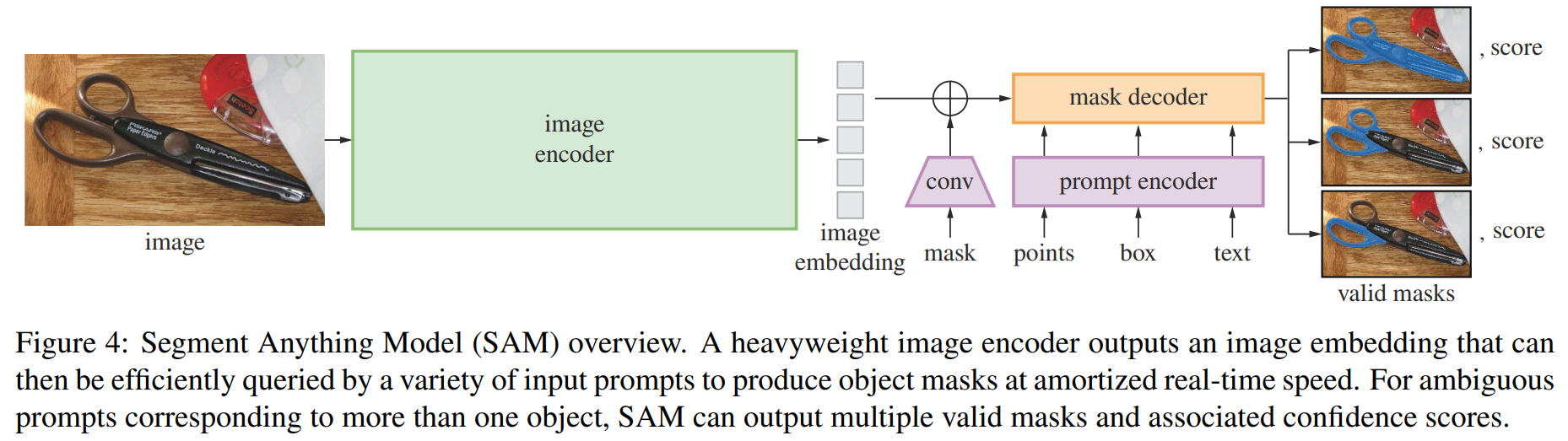
Image encoder
고해상도 입력을 처리하기 위해 최소한으로 조정된 MAE pre-trained Vision Transformer를 사용한다. 여기에서 MAE는 masked autoencoder로 역시 메타(Facebook AI reserach)에서 발표한 논문이다. 이미지 인코더는 이미지당 한번 실행되며 모델에 프롬프트하기 전에 적용할 수 있다. 그림에 나와 있는 설명처럼 이미지 인코더는 무겁다(heavyweight).
Prompt encoder
두 가지 프롬프트 세트를 고려한다: sparse(포인트, 박스, 텍스트), dense(마스크)
위치 인코딩과 학습된 임베딩을 더하는 방식으로 점과 박스를 표현한다. 텍스트의 경우 CLIP의 off-the-shelf(따로 조정 안했다는 의미인듯) 텍스트 인코더의 결과를 사용한다.(다만 텍스트 입력의 경우 github의 prompt_encoder.py에 처리하는 코드가 존재하지 않는다. 이 부분에 대해서는 다른 사람들이 실험한 데모가 있으니 관심있는 독자는 찾아보길 바란다.) 마스크의 경우 컨볼루션을 통해 embeded되고 이미지 임베딩과 element-wise하게 더해진다.
공식 코드를 통해 확인해 보자.
전반적인 이해를 위해서는 전체 코드를 한 번 살펴보는 것이 좋다. 프롬프트 인코더가 sparse, dense 입력을 어떻게 처리하는지 파악하기 위해 코드의 일부분을 제시한다.
아래는 포인트와 박스 입력이 들어왔을 때이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5 # Shift to center of pixel
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
point 기준으로 보면 foreground의 경우 labels은 1이고 background의 경우 labels는 0이 된다. pe_layer는 별도로 정의된 PositionEmbeddingRandom(nn.Module) 클래스이다. 아래는 해당 클래스이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C
이름에서도 알 수 있듯이 positional encoding을 수행하는 코드이다. 포인트 입력의 경우 라벨과 합쳐져서 들어간다. 이 부분은 기회가 되면 포인트와 박스 입력일때 정확히 어떤 프로세스를 거쳐서 output을 반환하는지 추론 코드 분석을 통해 리뷰하도록 하겠다.
+) register_buffers는 생소할 수 있는데 register_buffer의 경우 nn.Module 내에서 제공하는 모듈로 특정 이름으로 접근이 가능하게 되고 state_dict에 저장되지만 optimizer가 업데이트하지는 않는다. Optimzier 업데이트 가능한 register_parameters라는 모듈도 존재한다.
아래는 마스크 입력이 들어왔을 때이다.
1
2
3
4
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
1
2
3
4
5
6
7
8
9
10
11
12
13
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
1
2
3
4
5
6
7
8
9
10
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
여기에서 activation은 클래스의 init 메서드의 입력으로 전달되는 매개변수로 기본적으로 nn.GELU이다.
실제 사용과는 좀 다르겠지만 임의로 예시를 만들어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import torch
import torch.nn as nn
activation = nn.GELU
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class CustomModel(nn.Module):
def __init__(self, mask_in_chans, embed_dim):
super(CustomModel, self).__init__()
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
# example
mask_in_chans = 16
embed_dim = 32
masks = torch.randn(1, 1, 64, 64) # 샘플로 64x64 크기의 마스크 생성
model = CustomModel(mask_in_chans, embed_dim)
mask_embedding = model._embed_masks(masks)
print("Mask embedding shape:", mask_embedding.shape)
print(mask_embedding)
1
2
Mask embedding shape: torch.Size([1, 32, 16, 16])
...
mask_in_chans와 embed_dim은 미리 정의해야 한다. chans는 channels의 약자로 보인다. downsampling된 마스크가 embed_dim만큼의 채널 수를 가지게 된다.
Mask decoder
마스크 디코더는 이미지 임베딩, 프롬프트 임베딩을 출력 마스크로 매핑한다. 이 구조는 transformer 기반 segmentation 모델에 영감을 받았다고 한다.
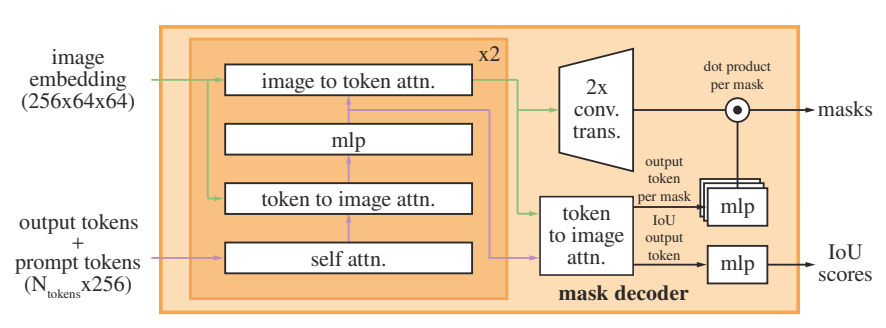
디코더 적용 이전에 디코더의 출력에 사용될 학습된 출력 토큰 임베딩(이하 간단하게 토큰이라 명명, 이미지 임베딩은 제외)을 프롬프트 임베딩 집합에 넣는다. 클래스 토큰은 vision transformer에서 착안한 것으로 보인다. 그림처럼 각 디코더 layer는
- 토큰에 대한 self-attention
- 토큰에서 이미지 임베딩(쿼리)로의 cross-attention
- 각 토큰을 업데이트하는 point-wise MLP
- 이미지 임베딩(쿼리)에서 토큰으로 cross-attention
의 4가지 스텝으로 구성된다.
Cross-attention 동안 이미지 임베딩은 ${64}^{2}$의 256-d 벡터로 처리된다. 여기에 self/cross-attention과 MLP는 residual connection이 있으며 layer normalization, dropout 0.1이 적용되어 있다.
2-layer 디코더를 사용하며 위치 인코딩은 이미지 임베딩이 attention layer에 들어갈때마다 추가되는데 이는 기하학적 정보를 디코더가 잘 이용할수 있도록 하기 위함이다. 추가적으로 위치 인코딩을 포함한 전체 original 프롬프트 토큰은 attention layer에 들어갈때마다 업데이트된 토큰에 다시 추가된다. 이렇게 함으로써 프롬프트 토큰의 기하학적 위치와 유형 모두에 강한 dependence를 갖는다고 설명한다.
디코더 실행 후 2개의 transposed conv layer를 사용하여 이미미 임베딩의 크기를 4배로 업샘플링한다.(입력 이미지에 비해 4배 축소 상태. 이는 입력이 $1024\times1024$이고 transposed conv의 stride가 2이기 떄문) 그리고 토큰은 이미지 임베딩에 다시 한 번 들어가고 업데이트된 출력 토큰 임베딩을 3-layer MLP에 전달하는데 이 MLP는 업스케일된 이미지 임베딩의 채널 차원과 일치하는 벡터를 출력한다. 마지막으로 업스케일된 이미지 임베딩과 MLP 출력간 spatial point-wise product을 통해 마스크를 예측한다.
추가적으로 트랜스포머와 컨볼루션의 채널 등 모델의 하이퍼파라미터에 및 계산에 대한 디테일이 조금 더 설명되어 있으나 생략하도록 한다.
Resolving ambiguity
만약 우리가 셔츠를 입고 있는 사람에 점을 찍어서 SAM 모델을 쓴다고 가정해보자. 이렇게 되면 단순히 셔츠를 segmentation할수도 있고 셔츠를 입고있는 사람 전체를 segmentation할수도 있다. 이런 하나의 입력 프롬프트가 여러 개의 유효한 마스크를 출력할 수 있다는 것을 ambiguous하다라고 표현한다. 모델은 이렇게 되면 유효한 마스크에 대한 평균을 학습하게 되는데 간단한 수정으로 이 문제를 해결했다고 한다. 하나의 마스크를 예측하는 대신에 여러 개의 마스크를 동시에 예측하는 것이다. 개수는 3개가 적당했다고 한다(전체, 부분 및 하위 부분이면 충분한 설명이다라고 주장).
Efficiency
이미지 임베딩이 주어진다면 프롬프트 인코더와 마스크 디코더는 CPU에서 50ms이내로 돌아가고 웹 브라우저에 출력된다. 다만 이미지 임베딩은 이미지 인코더로부터 얻어지고 이미지 encoder는 $1024\times1024$의 크기를 입력으로 받으며 논문에 “heavyweight”이라고 표현을 했으니 전체적인 시간은 조금 걸릴 수 있을 것으로 보인다. 논문의 limitation에도 무거운 이미지 인코더를 사용할 경우 실시간 사용에 어려움이 있음을 언급하고 있다.
Loss
Focal loss와 dice loss의 선형 결합으로 이루어지고 비율은 20:1로 나와있다.
이 논문의 아쉬운 점은 training 코드를 공개하지 않아 어떻게 학습시키고 loss를 설정했는지 설명으로만 이해를 해야 한다. 물론 이 논문의 loss는 간단하지만 training 및 loss의 경우 대다수의 논문이 설명과 실제 코드가 살짝 괴리가 있는 경우가 많다. (설명하지 않은 부분이 있다던지… 반대의 경우 포함 또는 loss에 가정과 수식은 장황하게 설명하였으나 실제 코드로는 평균으로 갈음하는 사례도 있음)
Loss에 대한 설명을 이어가자면 DETR이나 MaskFormer과는 달리 (둘다 facebook에서 발표한 논문) auxiliary deep supervision은 효과를 보지 못하였다고 적혀 있다. Deep supervision은 U-Net++에 사용된 개념으로 중간 layer의 출력도 추가적인 loss로 사용한 것이다.(layer별 loss를 평균하여 계산하였음) Training 코드가 공개되지 않아 정확한 파악은 어렵지만 어쨋든 deep supervision을 적용해 보았고 효과가 좋지 않았던 것 같다.
Training
Training 알고리즘
먼저 interactive segmentation을 시뮬레이션하기 위해 target mask를 위한 foreground 포인트와 bounding box 랜덤 확률 설정을 동일하게 만든다. 포인트는 균일하게 GT마스크에서 샘플링되고, 박스는 GT마스크의 bounding box로 설정되지만 사람이 tight하거나 loose하게 박스를 그릴 수 있는 점을 고려하여 10%, 최대 20픽셀의 노이즈를 좌표에 추가한다.
첫번째 프롬프트에서 예측 이후 이어지는 포인트가 GT와 마스크 예측 간의 error 영역에서 추출된다. 여기에서 새로운 포인트는 error region이 false negative이면 foreground, false positive이면 background이다. 또 이전 iteration의 마스크 예측을 추가적인 프롬프트로 모델에 입력한다. 여기에 최대한의 정보를 전달하기 위해 마스크를 logit을 통한 thresholding을 하지 않고 그대로 전달한다. 만약 복수의 마스크가 반환된다면 가장 높은 IOU를 가진 마스크를 선택한다.
포인트 샘플링을 16번까지 해봤으나 8번 iteration을 했을 때 성능이 떨어짐을 확인하였다. 추가적으로 모델에 들어가는 마스크의 이점을 활용하기 위해 샘플링된 추가 포인트 없이 2 iteration을 추가 수행한다. 그래서 처음에 input 프롬프트에서 1 iteration, 포인트 샘플링 8 iteration, 2개의 추가 iteration을 통해 총 11 iteration이 된다.
Training recipe
- AdamW optimizer사용 ($\beta_{1}=0.9,\;\beta_{2}=0.999$)
- batch size = 256
- iteration = 90000 (약 2 SA-1B epoch에 해당한다고 함. 계산상 256*90k/11M = 2.09…)
- learning rate warmup 사용 (250 iterations). warmup 이후 initial lr은 $8\mathrm{e}^{-4}$ lr은 60000 iteration과 86666 iteration에 10배씩 감소시킴
- weight decay 0.1
- drop path rate 0.4
- layer-wise lr decay 0.8
- data augmentation 적용안함
- GPU : A100 * 256 (68시간 학습)
Stackoverflow에 drop path와 dropout의 차이점을 설명하는 좋은 예시가 있다. 일반적으로 drop path는 residual connection과 같이 쓰이는 경우가 많다.
Automatic mask generation details
SA-1B 데이터 엔진 구축시 fully automatic stage에서 어떻게 마스크를 생성하는가에 대한 부분이다.
Cropping
마스크는 전체 이미지의 $32\times32$ 그리드 포인트 + 20개의 image crop $16\times16$, $8\times8$, 그리드 포인트(4+16=20)을 사용하여 생성한다. NMS를 (1) crop 내에 적용(IOU로 랭크), (2) crop간 적용(4*4 crop과 같은 가장 확대된 마스크부터 랭크)한다. 두 경우 모두 NMS threshold는 0.7로 적용했다고 한다.
Filtering
마스크의 품질을 높이기 위해 3가지의 필터를 사용했다고 한다.
- “confident”: 모델이 예측한 IOU가 0.88이상인 경우만 유지
- “stable”: logit을 -1로 설정했을 때의 binary 마스크, 1로 설정했을 때의 binary 마스크를 비교하여 IOU가 0.95이상이 것만 남김
- 자동 생성 마스크가 이미지의 95%이상을 차지하는 경우는 제거
Postprocessing
- 마스크 내의 픽셀 100픽셀 미만의 connected component는 제거(connected component가 정확히 뭔지는 조금 모호함)
- 마스크 내의 작은 구멍은 100픽셀 미만의 구멍은 채우는 방식으로 처리
model
추가로 일반 SAM과 마스크를 생성하기 위한 SAM은 모델 구조나 학습 iteration등이 조금 다르다고 기술되어 있다.
RAI analysis
RAI는 responsible AI의 약자이다. 이 부분은 데이터셋에 대해 여러 실험을 통해 성별, 인종, 피부톤에 대해 fair함을 보여준다.
Experiments
이 파트에서는 SAM의 여러 실험 및 결과를 제시한다. 제시된 그림 이외에도 appendix를 포함한 논문 전반에 걸쳐 많은 그림이 첨부되어 있다(RAI, vs RITM, human eval 등등).
아래 그림은 다양한 segmentation dataset에서 SAM의 결과를 보여준다.

아래 그림은 text prompt를 이용하여 마스크를 생성할 수 있음을 보여준다. SAM이 예측에 실패한다면 추가적인 포인트 프롬프트가 도움을 줄 수 있다고 한다.

아래 그림은 SAM이 edge detection을 수행할 수 있음을 보여준다. 마스크를 예측하고 소벨 필터를 적용했다고 한다.

결론
본 논문은 LLM과 같이 프롬프트를 입력으로 받아 segmentation할수 있는 foundation 모델의 개발을 목표로 하였다. 특징적인 점으로 생성된 mask는 특정한 클래스 라벨이 존재하지는 않는 점을 언급하고 싶다. 논문의 결과 이미지처럼 실제 웹 데모 혹은 코드로 테스트해보면 정성적으로 뛰어난 성능을 보여준다. 물론 픽셀간 차이가 모호간 경우나 내부에 중간중간 비어있는 object 및 경계 부분에서 약점이 보이기도 한다. 이미지 인코더에 고정된 이미지 크기 입력을 받는다는 것도 단점이다. 이후에 다른 연구진들이 Semantic-SAM이나 HQ-SAM과 같은 후속 연구를 발표하였으니 이 논문들을 읽어보는 것도 도움이 될 것 같다.
논문이 긴 편이라 디테일이 상당히 많다. 모든 내용을 담지는 못하였으며 공식 Github에 training 코드를 포함한 여러 부분들을 공개되어 있지 않기에 이해한 내용과 실제 구현에 차이가 있을 수 있다.
댓글남기기