Vision Transformer (1)
Vision Transformer란
Vision Transformer(ViT)는 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(2020) 라는 제목으로 발표되었다.
사실 제목에 답이 있는데, 이미지를 16x16으로 이루어진 단어들로 보겠다는 뜻이다.
그리고 이 말은 이미지 역시 트랜스포머를 이용한 자연어 처리와 같은 컨셉으로 진행하겠다는 뜻이다.
자연어 처리(NLP) 분야에서는 트랜스포머의 등장 이후 트랜스포머 기반 모델이 거의 장악을 하고 있는 실정인데, 컴퓨터 비전 분야에서는 CNN이 여전히 자리를 지키고 있었다.
비전 트랜스포머는 트랜스포머 구조를 컴퓨터 비전 분야에 적용하고자 하는 연구이다.(개인적으로는 철저하게 트랜스포머의 컨셉을 그대로 가져다 쓰고자 하는 느낌이다.)
아직 완벽하진 않지만 현재에 이르러서는 컴퓨터 비전의 여러 task에서 비전 트랜스포머 기반의 모델들이 SOTA를 달성하였다.
비전 트랜스포머 논문이 어려운 편에 속하는 논문은 아니지만 이를 이해하려면 어느 정도의 배경지식이 필요하다.
트랜스포머, 이를 응용한 BERT, self-attention 등 이를 다 설명하기에는 어렵고 비전 트랜스포머 이해가 가능한 정도까지만 나눠서 포스팅을 진행하고자 한다.
먼저 트랜스포머는 자연어 처리 분야에서 RNN, LSTM등의 문제점을 해결하기 위해 나온 구조이다.
트랜스포머는 제목인 Attention is all you need에서도 나타나듯이 attention이라는 컨셉을 사용하는데, 쉽게 이야기하자면 전체를 같은 비율로 참조하는게 아니라 유사성을 측정하여 예측과 관련된 부분을 더 주의 깊게 보는 것이다.
트랜스포머는 일반적으로 인코더-디코더 구조로 구성되어 있다.(예를 들어 번역의 경우 문장이 들어가서 문장이 나온다) 비전 트랜스포머는 기본적으로 분류 문제를 예시로 들고 오는데, 이 경우 클래스를 예측만 하면 되기 때문에 인코더에서 처리 후 다시 디코더를 통해 무언가로 돌려주는 과정이 필요없으므로 인코더만 존재한다.
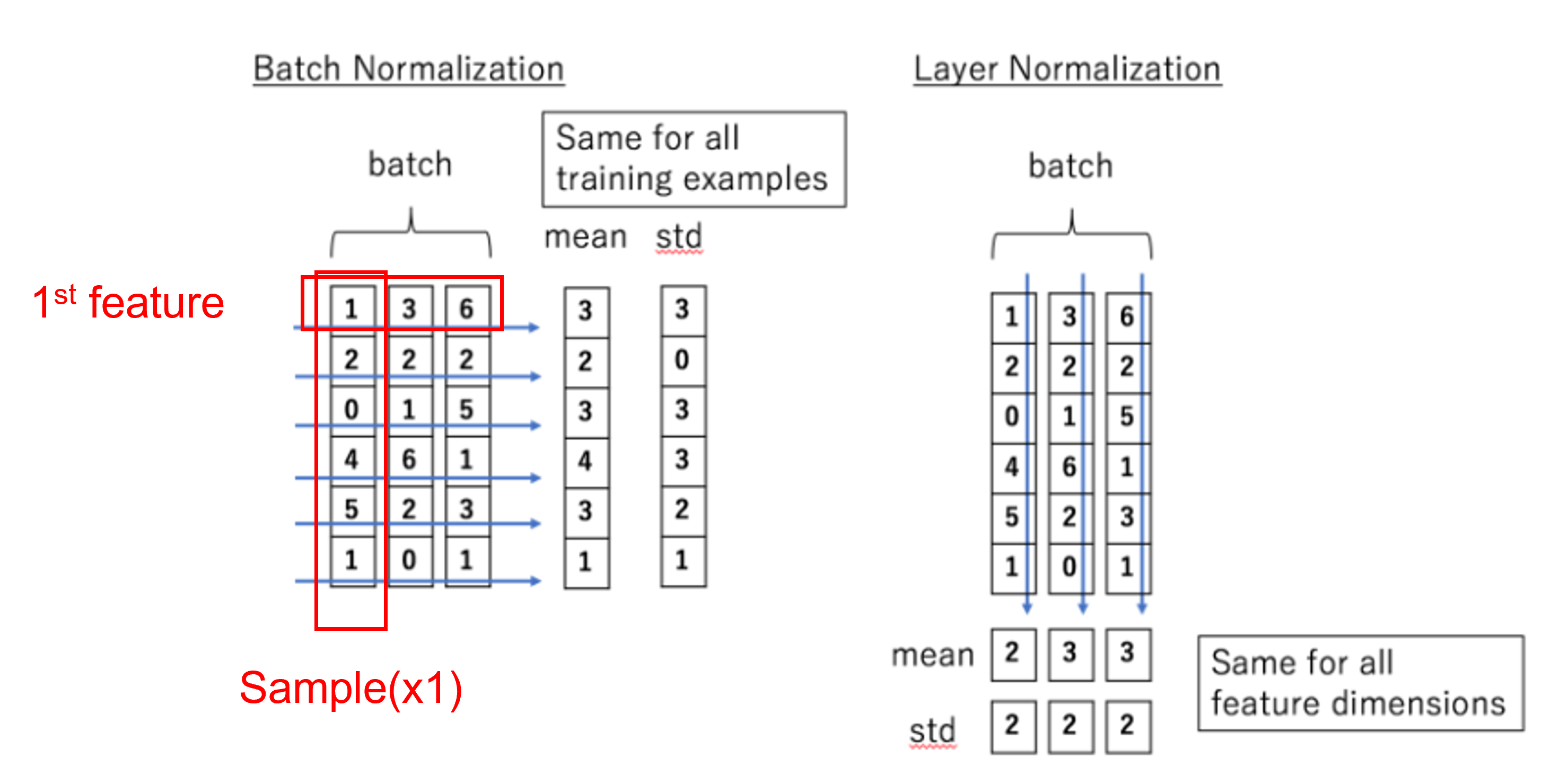
Batch Normalization(BN) vs Layer normalization(LN)
아래의 그림을 통해 BN과 LN의 차이점을 볼 수 있는데, BN은 각 샘플들의 feature를 정규화하고, LN은 각 샘플들을 정규화한다.
비전 트랜스포머에서는 LN을 사용한다.
각 샘플들을 정규화하기 때문에 입력 sequence에 길이 제약이 없는 트랜스포머의 특성을 그대로 가져왔다고 보면 된다.
Import and image
이제 본격적으로 코드와 함께 ViT가 어떻게 구성되어있는지 보려고 한다.
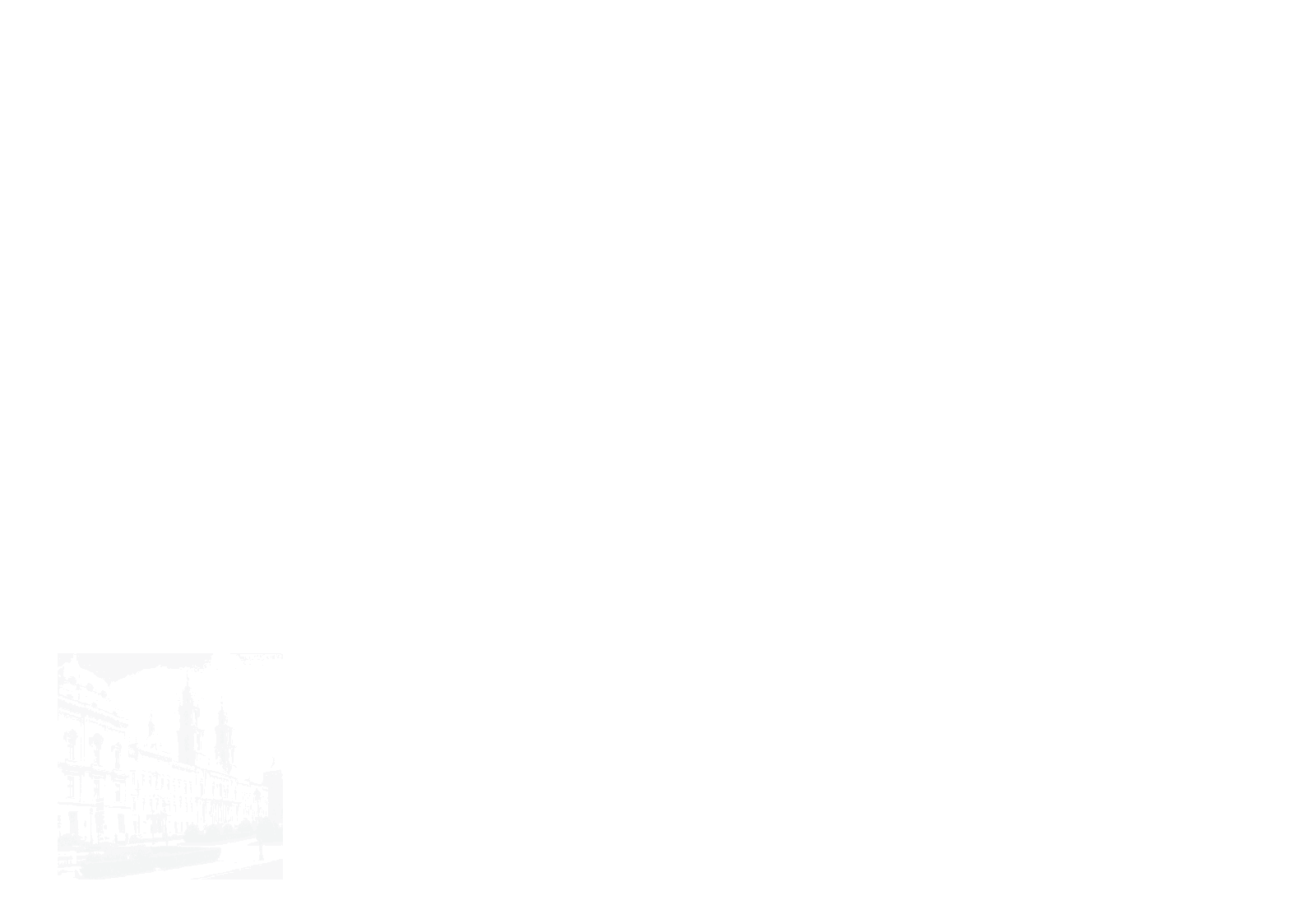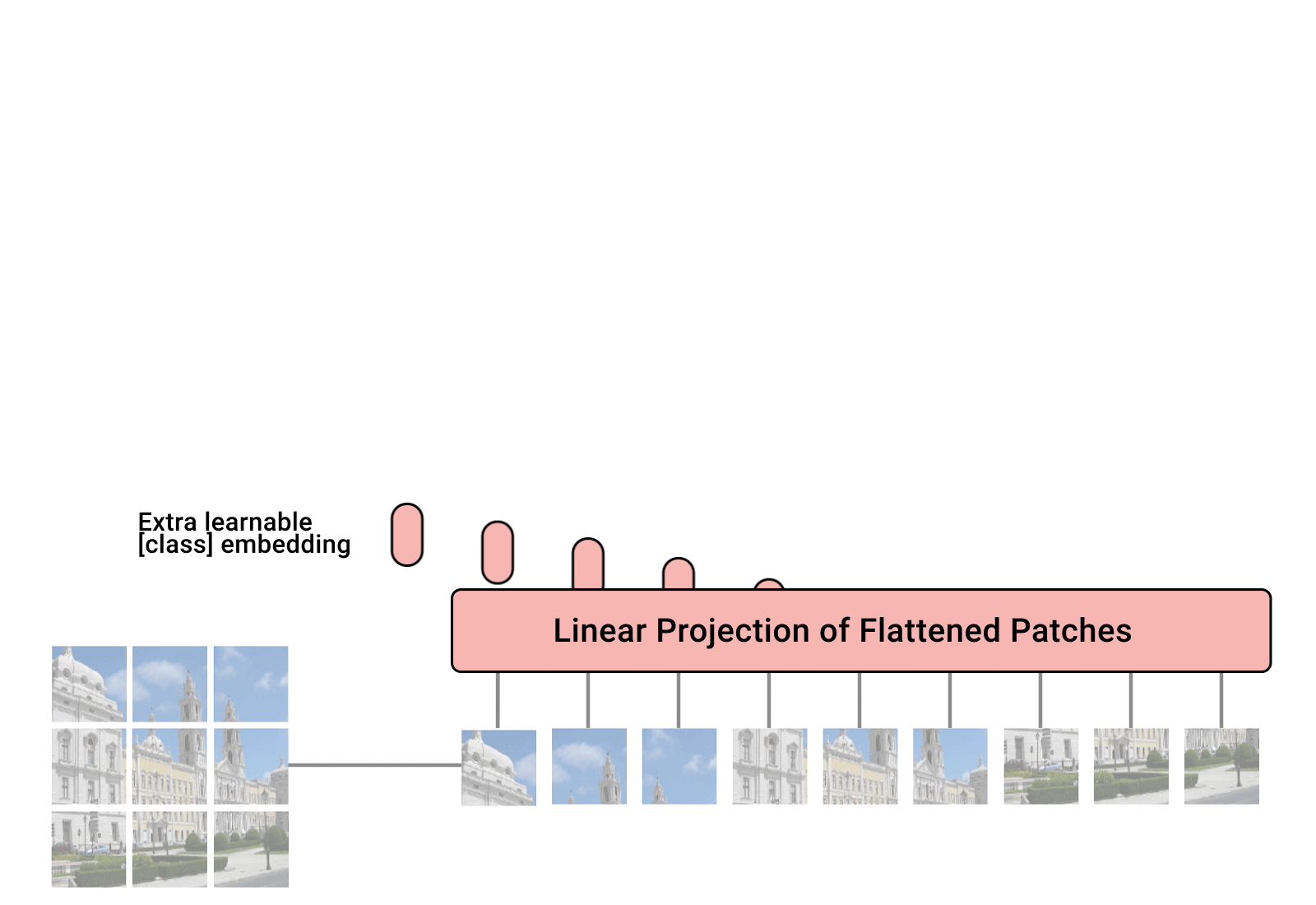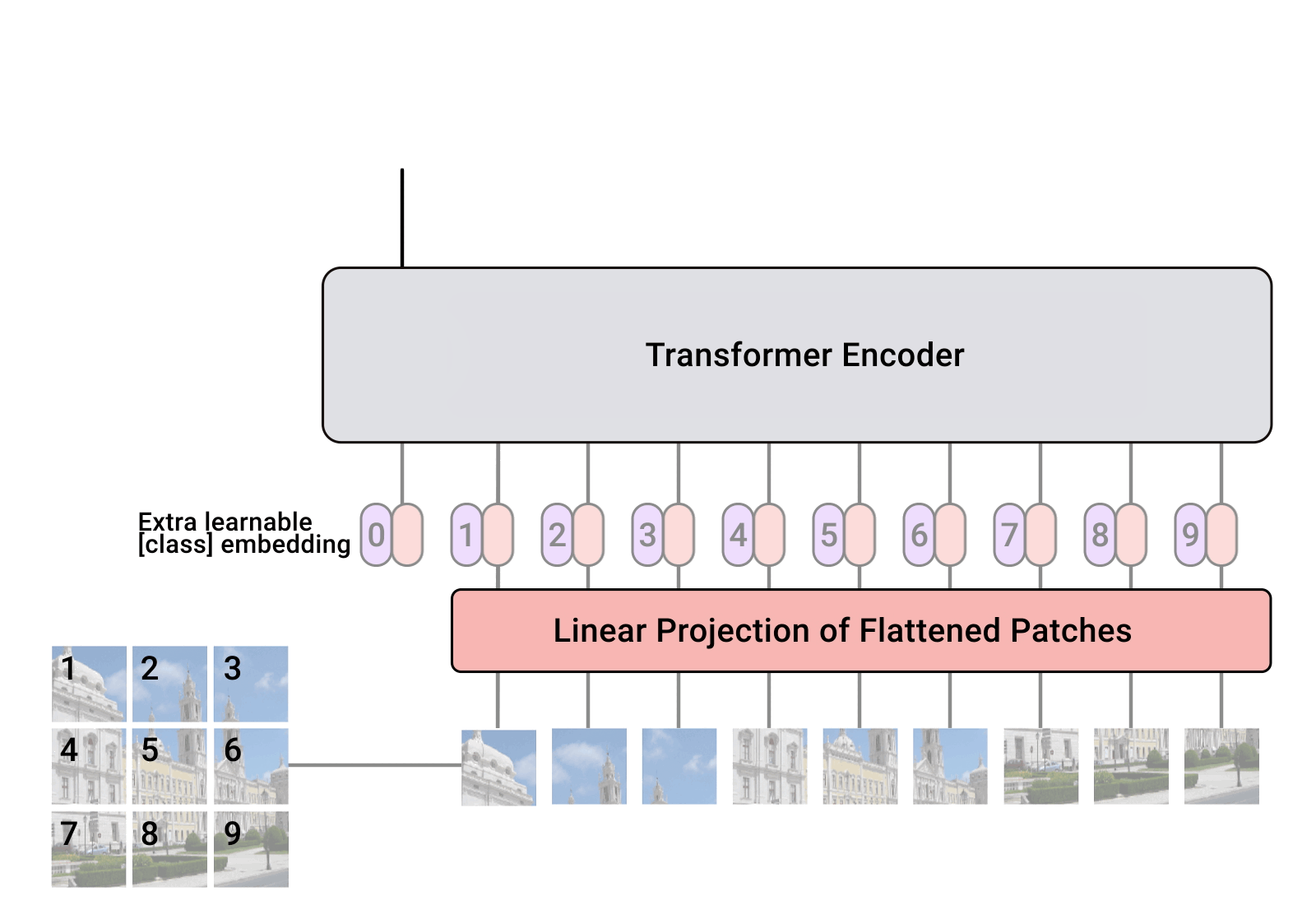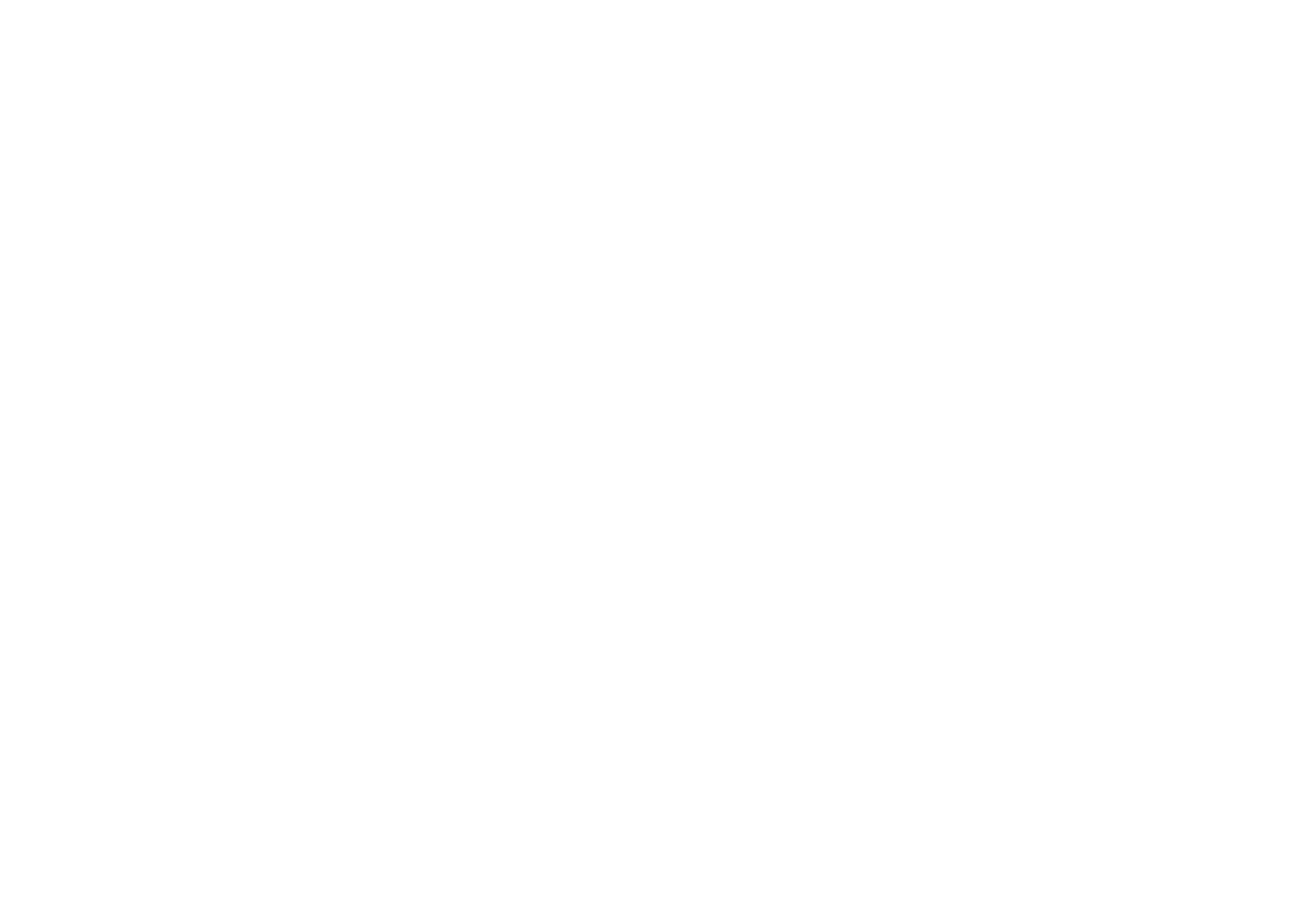
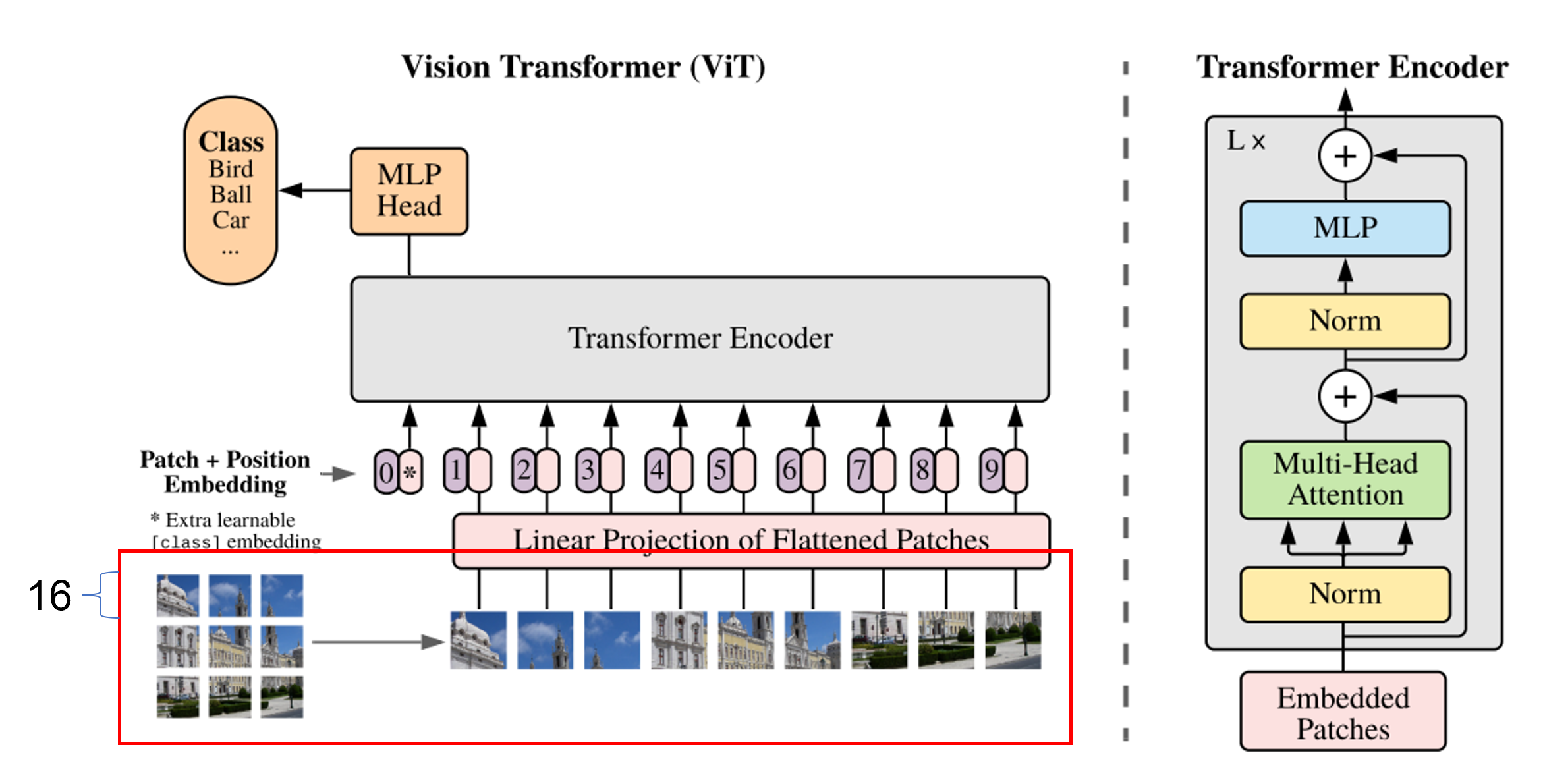
총체적으로 보면 입력 이미지가 패치로 나누어지고 flatten되어 transformer 인코더에 들어가고 multi-head attention을 거쳐 MLP와 결합하여 목적에 맞게 class를 예측한다.(분류 예시)
https://github.com/FrancescoSaverioZuppichini/ViT 에 pytorch와 기타 라이브러리를 이용하여 ViT를 구현하였고 이 코드를 분석해보고자 한다.
https://github.com/lucidrains/vit-pytorch/ 에는 ViT에 관련한 여러 논문을 코드로 구현해 놓았다.
이해를 위하여 코드에 추가적으로 주석을 표시하였다.
1
2
3
4
5
6
7
8
9
10
11
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
먼저 필요한 라이브러리들을 가져온다.
특이점은 einops인데 einstein operation의 약자로 tensor의 shape관련 작업을 수행할 때 굉장히 유용하다.
1
2
x = torch.randn(8, 3, 224, 224)
x.shape
1
torch.Size([8, 3, 224, 224])
ViT에 들어갈 데이터를 정의한다. batch size는 8이고 채널은 3(r,g,b), 이미지 크기(H,W)는 224x224이다.
Patches embeddings
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# [8,3,224,224]->[8,768,14,14]
Rearrange('b e (h) (w) -> b (h w) e'), # [8,768,14,14]->[8,196,768]
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
PatchEmbedding()(x).shape
1
torch.Size([8, 196, 768])
이미지를 패치로 잘라 임베딩하는 과정이다.
einops의 rearrange를 사용하여 $B\times C\times H\times W$ 의 이미지를 $B\times N\times (P^{2}\cdot C)$ 로 바꿔준다.
P는 패치의 크기이고 N은 $HW/P^{2}$ 이다. 예시에서는 $8\times 3\times (14\cdot 16)\times (14\cdot 16)$ 이 $8\times (14\cdot 14)\times (14\cdot 16\cdot 3)$ 으로 변한 것이다.
이미지를 패치로 나누고 flatten하는 이러한 과정을 patch embeddings라고 정의하고 있다.
코드에서도 나와 있듯이 linear 대신에 컨볼루션 layer를 사용하는데 이렇게 하면 성능 향상이 있다고 한다.
결과적으로 보면 16x16인 이미지를 단어 하나로 생각하고 이미지는 rgb이기 때문에 3을 곱한 768이 단어 하나가 되고, 이 단어가 196개가 있는 것이다.
Class token & Position embedding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'), #[8,196,768]
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size)) #class token [1,1,768]
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size)) #[197,768]
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b) #class token 반복(batch size)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1) #class token+x
# add position embedding
x += self.positions
return x
ViT에는 BERT와 유사하게 class token을 사용한다.
맨 앞에 학습가능한 class token을 추가하는데 BERT에서 이는 다른 단어와 구분되는 문장의 representation의 의미이고 ViT에서도 이러한 컨셉을 사용했다고 이해하였다.
Position embedding은 위치정보를 모델에 표현하기 위한 것인데, class token으로 인해 늘어난 shape에 맞추어 생성한다.
패치로 이미지를 잘랐기 때문에(혹은 문장에서 단어 단위로 구성되든) 직관적으로 이들의 위치 정보는 중요하다고 생각할 수 있다.
차이점으로는 ViT에서는 랜덤하게 초기화하여 사용하는데 원래 transformer에서는 sin/cos 함수로 사용한다.
이후의 multi-head attention부터 이어지는 부분은 다음 포스팅에서 설명하고자 한다.
댓글남기기