Vision Transformer (2)
Encoder
저번 포스팅의 position embedding에 이어 본격적인 ViT의 인코더 부분을 설명하고자 한다.
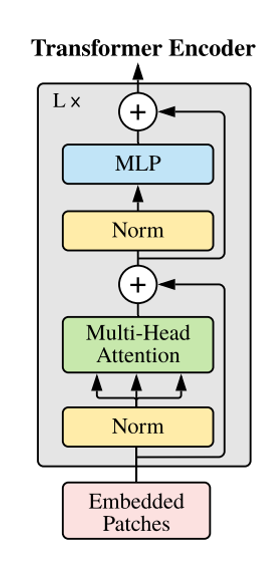
그림의 Norm은 layer normalization이고 입력이 그대로 더해지는 residual 구조를 가지고 있다.
Multi-Head Attention 라는 부분이 있는데 이를 알아보자.
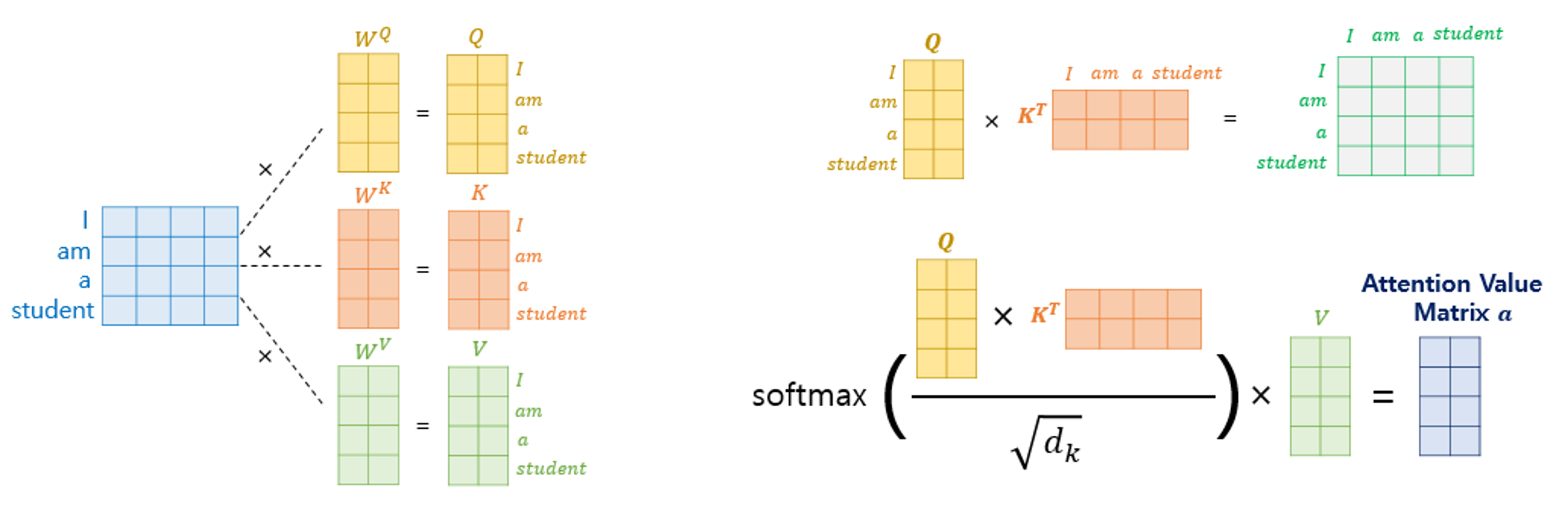
Q(query), K(key), V(value)의 의미는 어디에 쓰이느냐에 따라 조금씩 다르지만 여기서는 Q는 기준, K는 비교 대상 정도로 이해한다.
예를 들어 Chicks grow up to become chickens.라는 문장이 있으면 chicks랑 chickens는 연관이 있다는 것이다.
Q, K, V가 같은 input에서 유래되었으면 self-attention이라 부른다.
그림에 attention의 예시가 나와 있다.
먼저 입력 벡터에 Q, K, V를 만들어주는 행렬 W를 곱한다.
다음으로 $softmax(Q\times K^{T}/\sqrt{d_{k}} )\times V$ 를 통해 attention을 구한다.
이것의 의미는 q, k의 similarity를 구하는 것과 비슷한 의미이다.
즉, attention을 구하는 것은 input이 output에 얼마나 기여하는지를 구하는 것이다.
딥러닝에서는 $W_{qkv}$ 가 학습 가능한 파라미터로 작용한다.
이 작업을 여러 번 수행하면 multi-head attention이 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2) #sqrt(D_k)
att = F.softmax(energy/scaling, dim=-1)
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
torch의 einsum을 이용해 행렬곱을 구현한 것을 확인할 수 있다.
다만 if mask is not None: 의 조건문의 경우 softmax 결과를 0으로 만드는데 이 부분에 대해서는 고찰이 필요한 것 같다.
1
2
3
4
5
6
7
8
9
10
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
위의 코드는 residual connection을 구현한 것이다.
특별히 설명할 부분은 없다.
1
2
3
4
5
6
7
8
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
위의 코드는 MLP 부분인데 특이점으로는 여타 다른 트랜스포머와 같이 활성화함수로 GELU를 사용하였다.
GELU가 모든 점에서 미분 가능하다는 특징을 가지고 있으며 ReLU 적용 시 0이 많을 경우 발생할 수 있는 문제를 해결할 수 있다고 알려져 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
이를 종합하여 Encoder 생성이 가능하다.
nn.Sequential을 상속받았기 때문에 forward를 정의하지 않았다.
1
2
3
x = torch.randn(8, 3, 224, 224)
patches_embedded = PatchEmbedding()(x)
TransformerEncoderBlock()(patches_embedded).shape
1
torch.Size([8, 197, 768])
1
2
3
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
인코더를 몇 겹으로 생성할 것인지에 관한 코드이다.
Classification Head
1
2
3
4
5
6
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
최종적으로 클래스를 예측하기 위한 부분이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
앞서 정의한 클래스들을 이용하여 ViT가 완성되었다.
1
summary(ViT(), (3, 224, 224), device='cpu') #확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
PatchEmbedding-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 2304] 1,771,776
Dropout-6 [-1, 8, 197, 197] 0
Linear-7 [-1, 197, 768] 590,592
MultiHeadAttention-8 [-1, 197, 768] 0
Dropout-9 [-1, 197, 768] 0
ResidualAdd-10 [-1, 197, 768] 0
LayerNorm-11 [-1, 197, 768] 1,536
Linear-12 [-1, 197, 3072] 2,362,368
GELU-13 [-1, 197, 3072] 0
Dropout-14 [-1, 197, 3072] 0
Linear-15 [-1, 197, 768] 2,360,064
Dropout-16 [-1, 197, 768] 0
ResidualAdd-17 [-1, 197, 768] 0
LayerNorm-18 [-1, 197, 768] 1,536
Linear-19 [-1, 197, 2304] 1,771,776
Dropout-20 [-1, 8, 197, 197] 0
Linear-21 [-1, 197, 768] 590,592
MultiHeadAttention-22 [-1, 197, 768] 0
Dropout-23 [-1, 197, 768] 0
ResidualAdd-24 [-1, 197, 768] 0
LayerNorm-25 [-1, 197, 768] 1,536
Linear-26 [-1, 197, 3072] 2,362,368
GELU-27 [-1, 197, 3072] 0
Dropout-28 [-1, 197, 3072] 0
Linear-29 [-1, 197, 768] 2,360,064
Dropout-30 [-1, 197, 768] 0
ResidualAdd-31 [-1, 197, 768] 0
LayerNorm-32 [-1, 197, 768] 1,536
Linear-33 [-1, 197, 2304] 1,771,776
Dropout-34 [-1, 8, 197, 197] 0
Linear-35 [-1, 197, 768] 590,592
MultiHeadAttention-36 [-1, 197, 768] 0
Dropout-37 [-1, 197, 768] 0
ResidualAdd-38 [-1, 197, 768] 0
LayerNorm-39 [-1, 197, 768] 1,536
Linear-40 [-1, 197, 3072] 2,362,368
GELU-41 [-1, 197, 3072] 0
Dropout-42 [-1, 197, 3072] 0
Linear-43 [-1, 197, 768] 2,360,064
Dropout-44 [-1, 197, 768] 0
ResidualAdd-45 [-1, 197, 768] 0
LayerNorm-46 [-1, 197, 768] 1,536
Linear-47 [-1, 197, 2304] 1,771,776
Dropout-48 [-1, 8, 197, 197] 0
Linear-49 [-1, 197, 768] 590,592
MultiHeadAttention-50 [-1, 197, 768] 0
Dropout-51 [-1, 197, 768] 0
ResidualAdd-52 [-1, 197, 768] 0
LayerNorm-53 [-1, 197, 768] 1,536
Linear-54 [-1, 197, 3072] 2,362,368
GELU-55 [-1, 197, 3072] 0
Dropout-56 [-1, 197, 3072] 0
Linear-57 [-1, 197, 768] 2,360,064
Dropout-58 [-1, 197, 768] 0
ResidualAdd-59 [-1, 197, 768] 0
LayerNorm-60 [-1, 197, 768] 1,536
Linear-61 [-1, 197, 2304] 1,771,776
Dropout-62 [-1, 8, 197, 197] 0
Linear-63 [-1, 197, 768] 590,592
MultiHeadAttention-64 [-1, 197, 768] 0
Dropout-65 [-1, 197, 768] 0
ResidualAdd-66 [-1, 197, 768] 0
LayerNorm-67 [-1, 197, 768] 1,536
Linear-68 [-1, 197, 3072] 2,362,368
GELU-69 [-1, 197, 3072] 0
Dropout-70 [-1, 197, 3072] 0
Linear-71 [-1, 197, 768] 2,360,064
Dropout-72 [-1, 197, 768] 0
ResidualAdd-73 [-1, 197, 768] 0
LayerNorm-74 [-1, 197, 768] 1,536
Linear-75 [-1, 197, 2304] 1,771,776
Dropout-76 [-1, 8, 197, 197] 0
Linear-77 [-1, 197, 768] 590,592
MultiHeadAttention-78 [-1, 197, 768] 0
Dropout-79 [-1, 197, 768] 0
ResidualAdd-80 [-1, 197, 768] 0
LayerNorm-81 [-1, 197, 768] 1,536
Linear-82 [-1, 197, 3072] 2,362,368
GELU-83 [-1, 197, 3072] 0
Dropout-84 [-1, 197, 3072] 0
Linear-85 [-1, 197, 768] 2,360,064
Dropout-86 [-1, 197, 768] 0
ResidualAdd-87 [-1, 197, 768] 0
LayerNorm-88 [-1, 197, 768] 1,536
Linear-89 [-1, 197, 2304] 1,771,776
Dropout-90 [-1, 8, 197, 197] 0
Linear-91 [-1, 197, 768] 590,592
MultiHeadAttention-92 [-1, 197, 768] 0
Dropout-93 [-1, 197, 768] 0
ResidualAdd-94 [-1, 197, 768] 0
LayerNorm-95 [-1, 197, 768] 1,536
Linear-96 [-1, 197, 3072] 2,362,368
GELU-97 [-1, 197, 3072] 0
Dropout-98 [-1, 197, 3072] 0
Linear-99 [-1, 197, 768] 2,360,064
Dropout-100 [-1, 197, 768] 0
ResidualAdd-101 [-1, 197, 768] 0
LayerNorm-102 [-1, 197, 768] 1,536
Linear-103 [-1, 197, 2304] 1,771,776
Dropout-104 [-1, 8, 197, 197] 0
Linear-105 [-1, 197, 768] 590,592
MultiHeadAttention-106 [-1, 197, 768] 0
Dropout-107 [-1, 197, 768] 0
ResidualAdd-108 [-1, 197, 768] 0
LayerNorm-109 [-1, 197, 768] 1,536
Linear-110 [-1, 197, 3072] 2,362,368
GELU-111 [-1, 197, 3072] 0
Dropout-112 [-1, 197, 3072] 0
Linear-113 [-1, 197, 768] 2,360,064
Dropout-114 [-1, 197, 768] 0
ResidualAdd-115 [-1, 197, 768] 0
LayerNorm-116 [-1, 197, 768] 1,536
Linear-117 [-1, 197, 2304] 1,771,776
Dropout-118 [-1, 8, 197, 197] 0
Linear-119 [-1, 197, 768] 590,592
MultiHeadAttention-120 [-1, 197, 768] 0
Dropout-121 [-1, 197, 768] 0
ResidualAdd-122 [-1, 197, 768] 0
LayerNorm-123 [-1, 197, 768] 1,536
Linear-124 [-1, 197, 3072] 2,362,368
GELU-125 [-1, 197, 3072] 0
Dropout-126 [-1, 197, 3072] 0
Linear-127 [-1, 197, 768] 2,360,064
Dropout-128 [-1, 197, 768] 0
ResidualAdd-129 [-1, 197, 768] 0
LayerNorm-130 [-1, 197, 768] 1,536
Linear-131 [-1, 197, 2304] 1,771,776
Dropout-132 [-1, 8, 197, 197] 0
Linear-133 [-1, 197, 768] 590,592
MultiHeadAttention-134 [-1, 197, 768] 0
Dropout-135 [-1, 197, 768] 0
ResidualAdd-136 [-1, 197, 768] 0
LayerNorm-137 [-1, 197, 768] 1,536
Linear-138 [-1, 197, 3072] 2,362,368
GELU-139 [-1, 197, 3072] 0
Dropout-140 [-1, 197, 3072] 0
Linear-141 [-1, 197, 768] 2,360,064
Dropout-142 [-1, 197, 768] 0
ResidualAdd-143 [-1, 197, 768] 0
LayerNorm-144 [-1, 197, 768] 1,536
Linear-145 [-1, 197, 2304] 1,771,776
Dropout-146 [-1, 8, 197, 197] 0
Linear-147 [-1, 197, 768] 590,592
MultiHeadAttention-148 [-1, 197, 768] 0
Dropout-149 [-1, 197, 768] 0
ResidualAdd-150 [-1, 197, 768] 0
LayerNorm-151 [-1, 197, 768] 1,536
Linear-152 [-1, 197, 3072] 2,362,368
GELU-153 [-1, 197, 3072] 0
Dropout-154 [-1, 197, 3072] 0
Linear-155 [-1, 197, 768] 2,360,064
Dropout-156 [-1, 197, 768] 0
ResidualAdd-157 [-1, 197, 768] 0
LayerNorm-158 [-1, 197, 768] 1,536
Linear-159 [-1, 197, 2304] 1,771,776
Dropout-160 [-1, 8, 197, 197] 0
Linear-161 [-1, 197, 768] 590,592
MultiHeadAttention-162 [-1, 197, 768] 0
Dropout-163 [-1, 197, 768] 0
ResidualAdd-164 [-1, 197, 768] 0
LayerNorm-165 [-1, 197, 768] 1,536
Linear-166 [-1, 197, 3072] 2,362,368
GELU-167 [-1, 197, 3072] 0
Dropout-168 [-1, 197, 3072] 0
Linear-169 [-1, 197, 768] 2,360,064
Dropout-170 [-1, 197, 768] 0
ResidualAdd-171 [-1, 197, 768] 0
Reduce-172 [-1, 768] 0
LayerNorm-173 [-1, 768] 1,536
Linear-174 [-1, 1000] 769,000
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 364.33
Params size (MB): 329.65
Estimated Total Size (MB): 694.56
----------------------------------------------------------------
Conclusion
논문에서는 ViT의 패치 크기가 작으면 연산량은 늘어나지만 성능은 좋아진다고 설명한다.
또한 Large Dataset에 대해서 잘 작동한다고 설명하고 있다.
다만 ViT도 나온지 어느 정도 시간이 지났고 현재(2023.01 기준) 특히 데이터가 부족한 의료 영상 분야에서도 여러 task의 SOTA 모델이 ViT 기반인 것을 감안해 보면 이러한 문제가 어느 정도 해결된 것으로 보인다.
ViT는 attention을 이용하여 모델에 대한 설명력도 제공하는데 attention rollout 이라는 트릭을 이용하여 집중 영역을 강조하기도 한다.
이 부분에 대해서는 기회가 될 때 코드와 함께 포스팅할 수 있으면 좋을 것 같다.
댓글남기기