Style LoRA 학습결과 (Qwen-Image-2512)
Introduction
오랫동안 플레이해왔던 게임 메이플스토리 배경을 컨셉으로 Style LoRA를 학습해 보았다.

1
2
3
4
5
maplestorybg, a 2D side scrolling background, oriental fantasy theme,
a large vertical hanging scroll standing in the center with a green dragon and golden patterns,
floor made of long unrolled scrolls, blooming pink cherry blossom trees,
misty mountains and stylized clouds in the background, soft pastel sunset sky, floating petals,
serene and magical atmosphere
인물, 텍스트가 존재하지 않는 배경 이미지를 중심으로 수집하여 150여 장의 이미지(인게임이 아닌 wallpaper와 같은 이미지도 포함)에 대한 캡셔닝을 진행하였다. Gemini를 활용한 자동 캡셔닝을 진행하였으며 10장 정도의 이미지에 대해서만 프롬프트 교정 작업을 수행하였다.
핵심 키워드는 maplestorybg, a 2D side scrolling background이다.
Training
학습을 위한 Base model은 Qwen-Image-2512를 사용하였다.
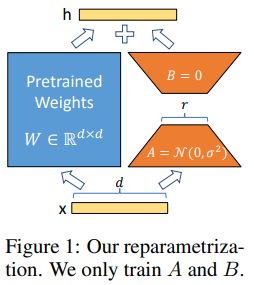
Qwen은 flow matching 기반 모델이다. Flow matching 기법은 vector field를 예측하는 방식으로 학습하며 나중에 샘플링 시에도 ODE 기반의 샘플러를 사용해야 한다.
내부적으로는 text encoder(Qwen2.5-VL에서 vision부분을 받지 않는 형태), diffusion transformer(DiT), VAE로 이루어져 있는데 여기에서 DiT에 있는 모든 linear, conv layer를 미리 정의된 lora_dim(rank)를 입력받아 down/up 행렬곱의 형태로 교체하는 식이다.
1
2
3
4
5
6
7
8
9
10
#if conv
self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=use_bias)
#if linear
self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=use_bias)
torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
torch.nn.init.zeros_(self.lora_up.weight)
예를 들면 Linear layer에서
(in=3584, out=3584) rank64이면
원래는 3584x3584 학습이
down(3584, 64)
up(64, 3584) 로 분해되어 최종적으로는 (3584, 3584)가 되고 원본 output에 더해진다.
conv의 경우도 기본적인 개념은 동일하다.
대신에 lora up의 경우 kernel은 1x1을 사용한다.
Spatial feature는 down에서 추출하고 up에서는 shape만 맞춰주면 된다는 느낌으로 이해하면 좋을 듯 하다.
디테일적으로는 1x1 conv는 원래 linear rank와 동일한 값을 사용하고 3x3은 따로 정의된 conv rank(ex. 16)로 작동한다.
또한 down은 랜덤, up은 0으로 초기화해서 행렬곱을 0으로 만들어 초기는 원본 모델과 동일하게 한다. 이는 Microsoft의 구현과 동일하다.
결국 rank에 따라 얼마나 많은 파라미터를 학습할지 정할 수 있으며 64를 사용하였다. 인물 LoRA는 보통 이보다 낮은 값을 사용한다.
핵심 training recipe는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
linear_rank: 64
conv_rank: 16
batch_size: 2
steps: 6400
gradient_accumulation: 1
resolution:
- 1024
- 1280
scheduler: "flowmatch"
loss: "mse"
dtype: bf16
ema_deacy: 0.99
learning_rate: 5e-5
Result
Sampler
Qwen-Image 모델은 flow matching 기반 모델이므로 ODE 기반 샘플러를 선택하는 것이 적절하다.
Flowmatch(Euler): 좌 / Heun: 우
Heun이 느리지만 고품질의 이미지를 생성할 수 있다고는 하나 정성적으로 봤을 때 Euler가 더 우수한 경우도 있었다.

LoRA scale
학습한 LoRA 모델의 강도를 조절할 수 있다.
original output + scale * lora output의 형태이다.
당연히 0이면 base 모델만 사용한 결과가 나온다.
스케일을 올릴수록 스타일이 강하게 반영되는 것을 확인할 수 있다.
보통 LoRA 모델은 0.8~1.2 정도의 값을 사용한다.

CFG scale
프롬프트에 대한 충실도이다.
1
pred = neg_pred + cfg_scale * (pos_pred - neg_pred)
pred는 noise/velocity와 같은 모델이 예측하는 값이다.
positive와 negative 각각의 예측을 따로 계산하여 noise/velocity 예측 단에서 합쳐준다.
낮을수록 샘플의 다양성이 있고 높을수록 프롬프트를 충실하게 따라간다.
값을 곱해주는 과정이기 때문에 scale을 맞추기 위해 결합 이후 normalization을 수행한다.
(normalization을 수행하는 것이 일반적이라 단언하긴 어렵고 수행하지 않는 경우도 있다.)
너무 높게 설정하면 이미지 collapse가 일어난다.

Step
샘플링을 얼마만큼 수행할지에 대한 설정값이다.
Diffusion 계열에서는 노이즈를 제거하는 과정이므로 step마다 랜덤한 노이즈를 추가하지 않는 deterministic한 샘플러의 경우 일반적으로 step이 커질수록 수렴하는 경향을 보인다.
다만 flow matching은 벡터 필드를 적분하여 샘플을 생성하는 ODE 기반 구조이므로, step이 늘어나면 연속 시간 trajectory에 대한 수치적 근사 정밀도를 향상시킨다. 반대로 step이 너무 작으면 적분 오차가 커져 샘플 품질 저하를 유발할 수 있다.

Conclusion
학습에서 조절할 수 있는 것은 데이터, base 모델, hyperparameter인데 역시 데이터가 가장 중요하다. 학습 데이터는 대부분 거의 다른 테마로 학습하였으며 프롬프트의 경우 Gemini를 활용한 자동 캡셔닝을 수행하였기에 배경이나 디테일을 자세히 설명하지 못한 이미지들이 많다. LoRA 모델의 퀄리티를 더욱 높이고 싶다면 내용이 어느 정도 중복되는 이미지 및 정밀한 프롬프트가 필요하다고 생각된다.
Reference
- https://qwen.ai/blog?id=qwen-image-2512
- https://arxiv.org/abs/2106.09685
댓글남기기