RL Course by David Silver - Lecture 1: Introduction to Reinforcement Learning
강화학습은 시간이 중요하다. 순차적인 결정의 연속이다.
예시
- 비행 곡예
- (+) 예상되는 경로 추종 시
- (-) 추락
- Backgammon 게임
- (+) 승리
- (-) 패배
- 투자 포트폴리오 관리
- (+) 돈
- 발전소
- (+) 전력 생산
- (-) 규제 위반
- 휴머노이드 로봇
- (+) forward motion
- (-) fallin over
- Atari 게임(pong 등)
- (+/-) 점수
Atari 게임의 경우 당시 GPU로 3~4일 학습 시 인간 수준의 성능 (게임마다 새로 학습)
보상 $R_{t}$ : scalar feedback signal. 시점 $t$에서 얼마나 잘하는가 모든 목표는 기대 보상의 최대화 라는 가정에 기반한다 Agent목표: 에피소드가 끝날 때 기대되는 보상의 합을 최대화
Q: 최대한 빠른 시간 내에 무언가를 해야하는 경우는 어떻게 하는가? A: 보상 신호를 시간 단계마다 -1로 정의한다
Goal: 미래 보상을 최대화할수 있는 action을 고르는 것 예시: 투자, 헬리콥터의 연료 보충
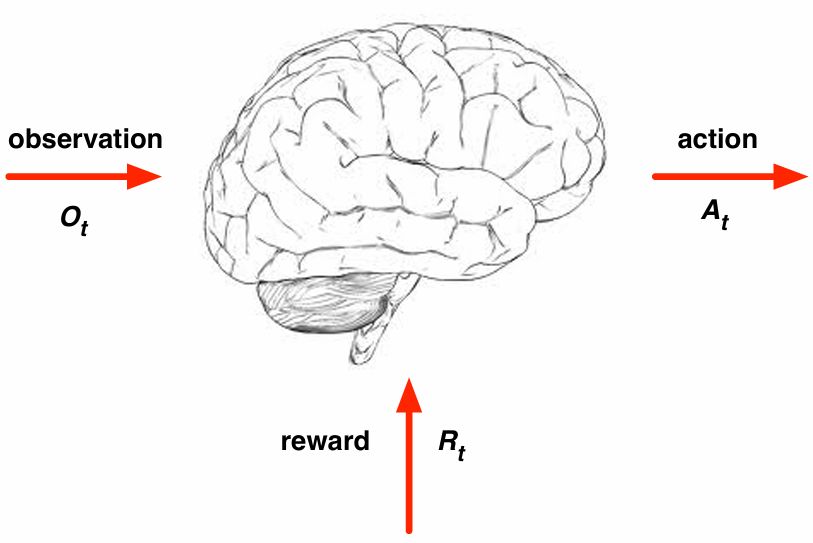
Agent를 뇌로 표현하면 목표는 뇌에 들어갈 알고리즘을 만드는 것.
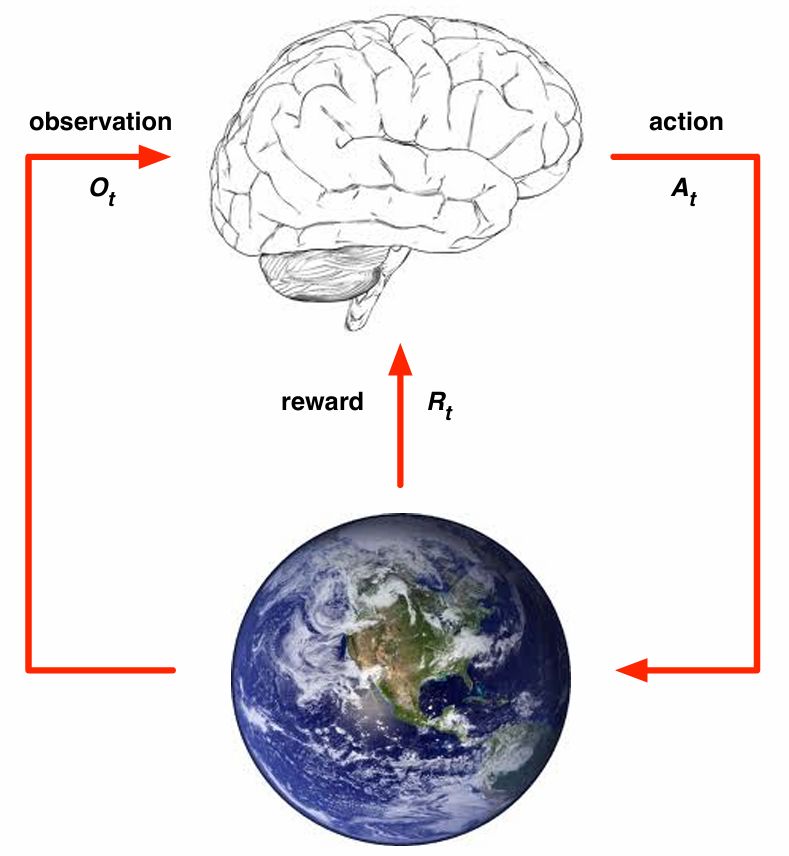
Environment(ex. Atari 게임)를 유리하게 변화시킬 수 있는 것은 action 보상은 항상 스칼라로 정의되어야 한다.
History: observation, action, reward의 sequence
\[H_{t} = A_{1}, O_{1}, R_{1}, ..., A_{t}, O_{t}, R_{t}\]history는 매우 방대해서 사용하기 어렵고 상태(state)라는 개념을 도입한다.
State: 다음에 무슨 일이 일어날지 결정하는 데 사용되는 정보의 요약
\[S_{t} = f(H_{t})\]역사의 어떤 함수든 상태라고 할 수 있다. ex. 마지막만 본다던지 이전의 4step만 관찰
$S^{a}_{t}$ 환경에 대한 상태는 볼 수 없고 agent에 대한 상태는 볼 수 있다.(알고리즘 내부에 있는 숫자들의 집합) 이 정보를 이용하여 다음 action을 선택한다.
\[S^{a}_{t} = f(H_{t})\]information state (Markov State)
\[\mathbb{P}[S_{t+1} \mid S_t] = \mathbb{P}[S_{t+1} \mid S_1, \ldots, S_t]\]markov state는 현재 state만 알면 과거의 모든 것을 버려도 된다 ex. 헬리콥터 제어
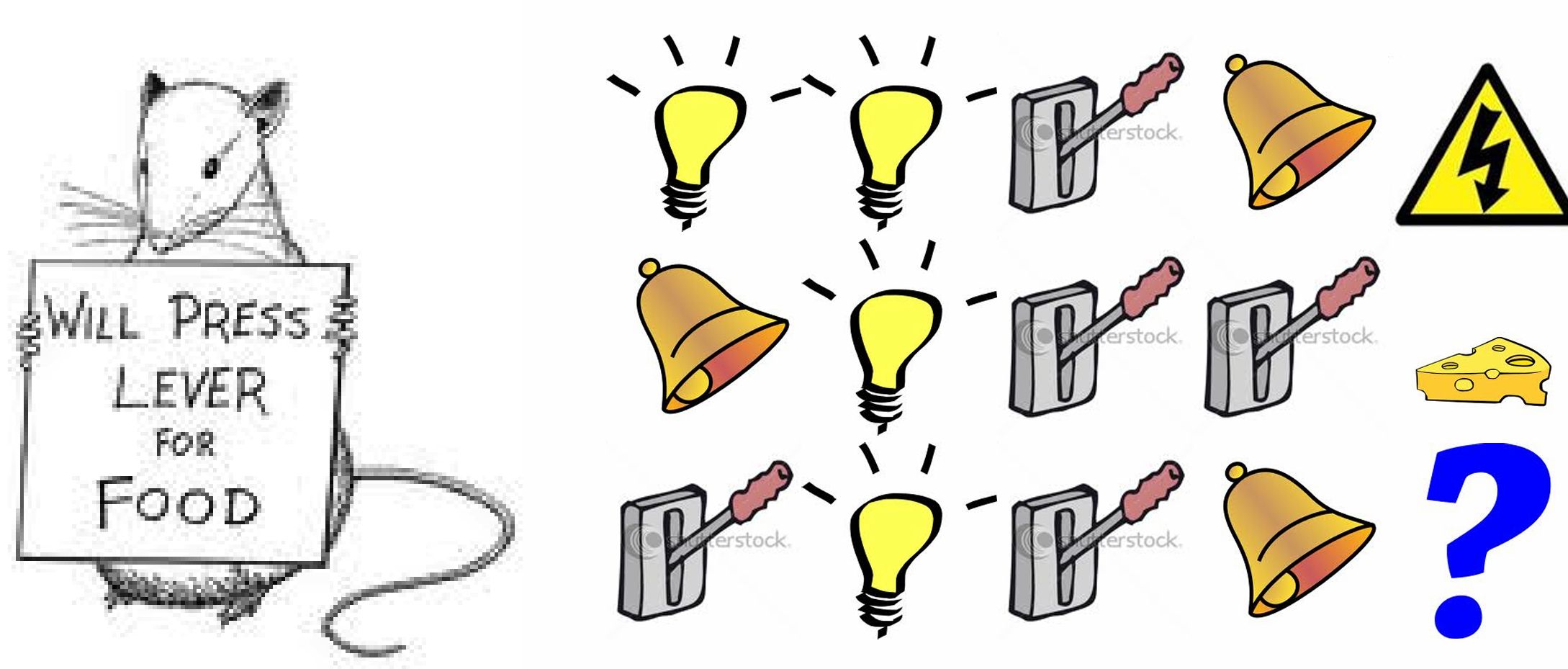
감전 or 치즈 최근3개이면 감전, 레버의 횟수면 치즈
Full obserevability (이상적인 케이스): 에이전트가 직접 environment state를 관측할 수 있는 경우
\[O_{t} = S^{a}_{t} = S^{e}_{t}\]–> Markov decision process
Partial obserevability: 에이전트가 간접적으로 환경을 관측
- 카메라 달린 로봇의 절대 위치
- 트레이딩 에이전트
- 포커 에이전트 (공개된 카드만 관찰)
–> POMDP
\[S^{a}_{t} = H_{t}\]Beliefs on environment state:
\[S_t^{a} = \left( \mathbb{P}[S_t^{e} = s^{1}], \ldots, \mathbb{P}[S_t^{e} = s^{n}] \right)\](모든 것에 대한 확률 유지)
Recurrent neural network:
\[S_t^{a} = \sigma \left( S_{t-1}^{a} W_s + O_t W_o \right)\]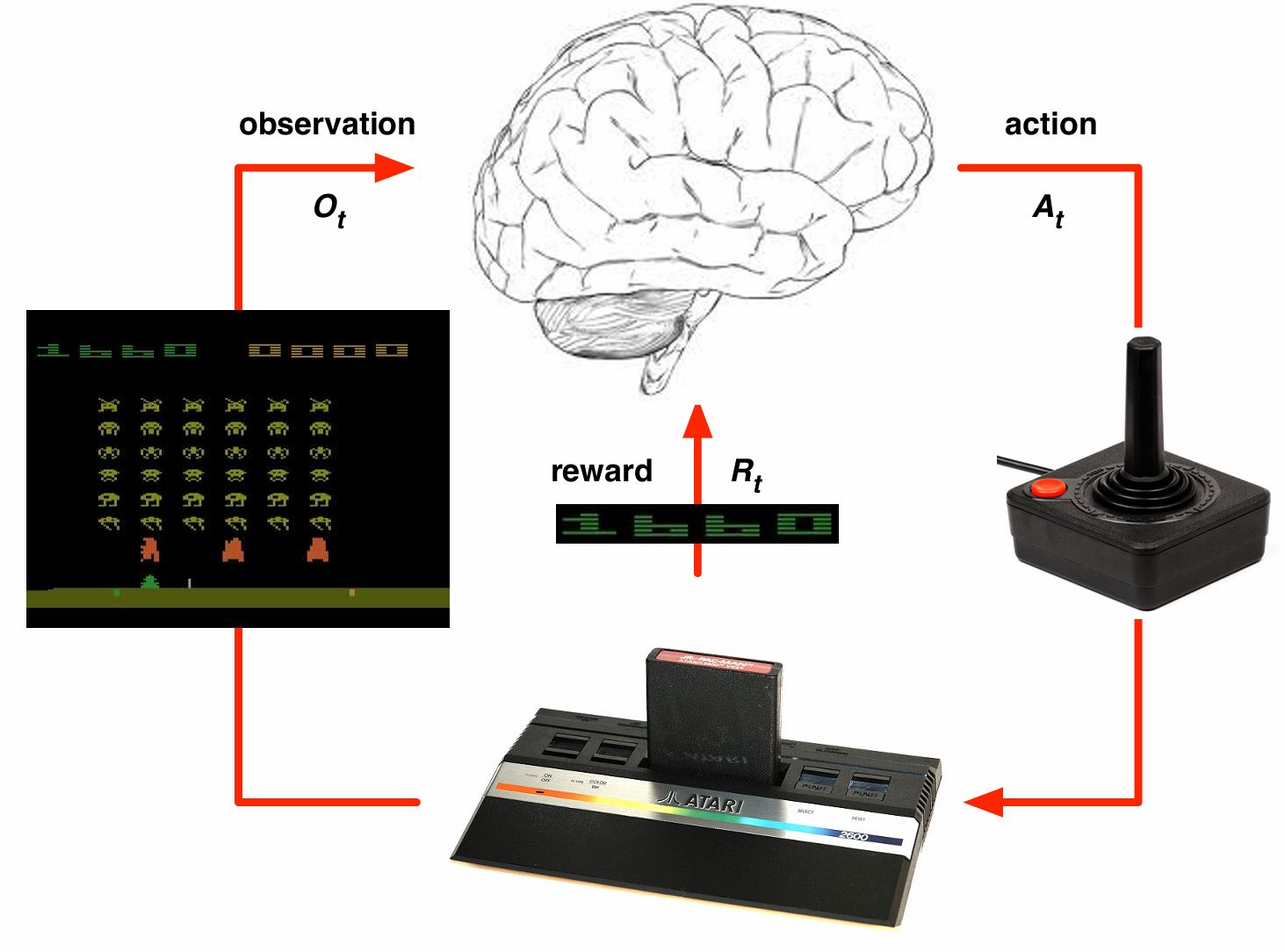
아타리 게임 실제 환경: 게임 카트리지 1024 이진수가 상황 나타냄
- Policy: 에이전트가 현재 상태에서 어떤 행동을 취할지 결정하는 방식 (behaviour function)
- Agent’s behaviour
- 상태에서 행동으로의 매핑
- Deterministic policy: $a = \pi(s)$
- 상태를 통해 정책을 만들고 이것이 가장 큰 보상으로 이어지게 하고 싶다
- Stochastic policy: $\pi(a\mid s) = \mathbb{P}[A=a\mid S=s]$
- 상태 공간을 더 많이 탐색하기 위해 무작위적인 탐색적 결정을 내릴수도 있음
- Value function: state나 action이 얼마나 좋은지 평가하는 함수. 가치함수.
- prediction of future reward
- $v_{\pi}(s) = \mathbb{E}{\pi} \left[ R{t+1} + \gamma R_{t+2} + \gamma^{2} R_{t+3} + \cdots \mid S_t = s \right]$
- 행동 방식에 따라 달라지므로 $\pi$로 인덱싱해야 한다.
- 현재에 더 가중치를 주는 방식으로 $\gamma$(감가율;discount)를 적용할 수 있다.
- ex. 로봇 일어서서 가기, 자동차 궤적 따라가기
아타리의 value function
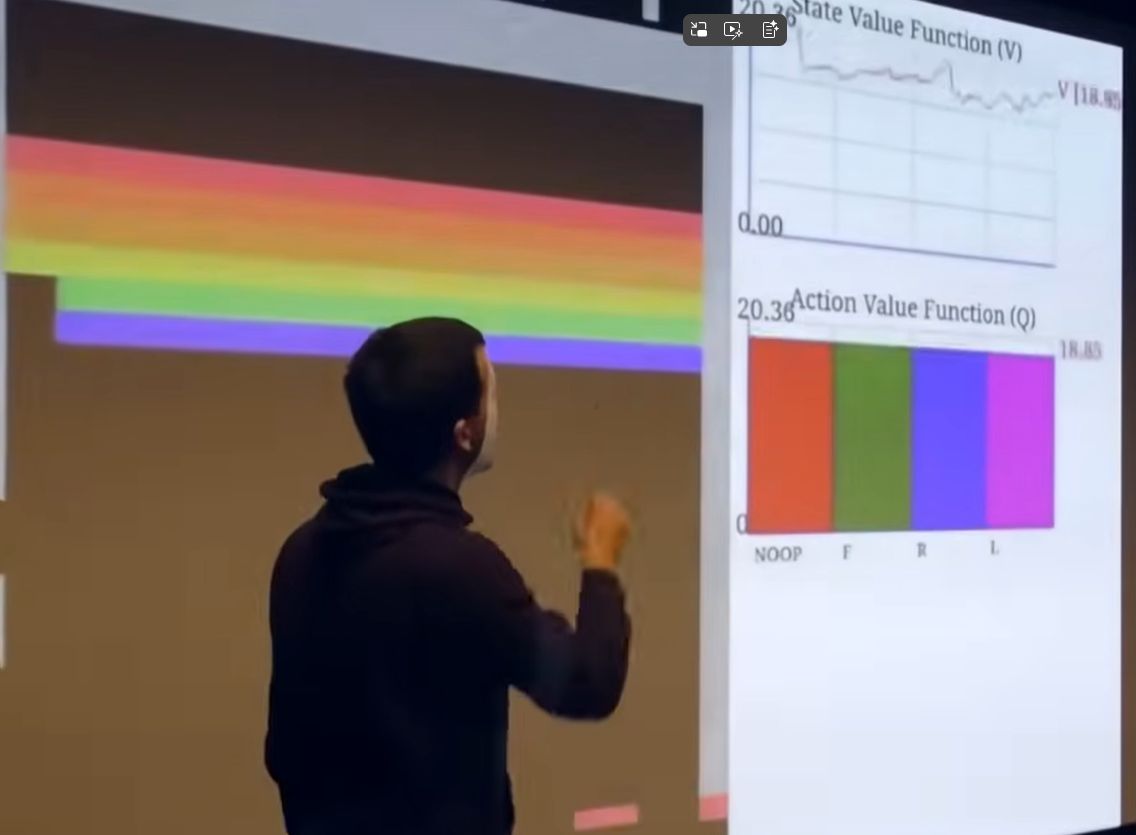
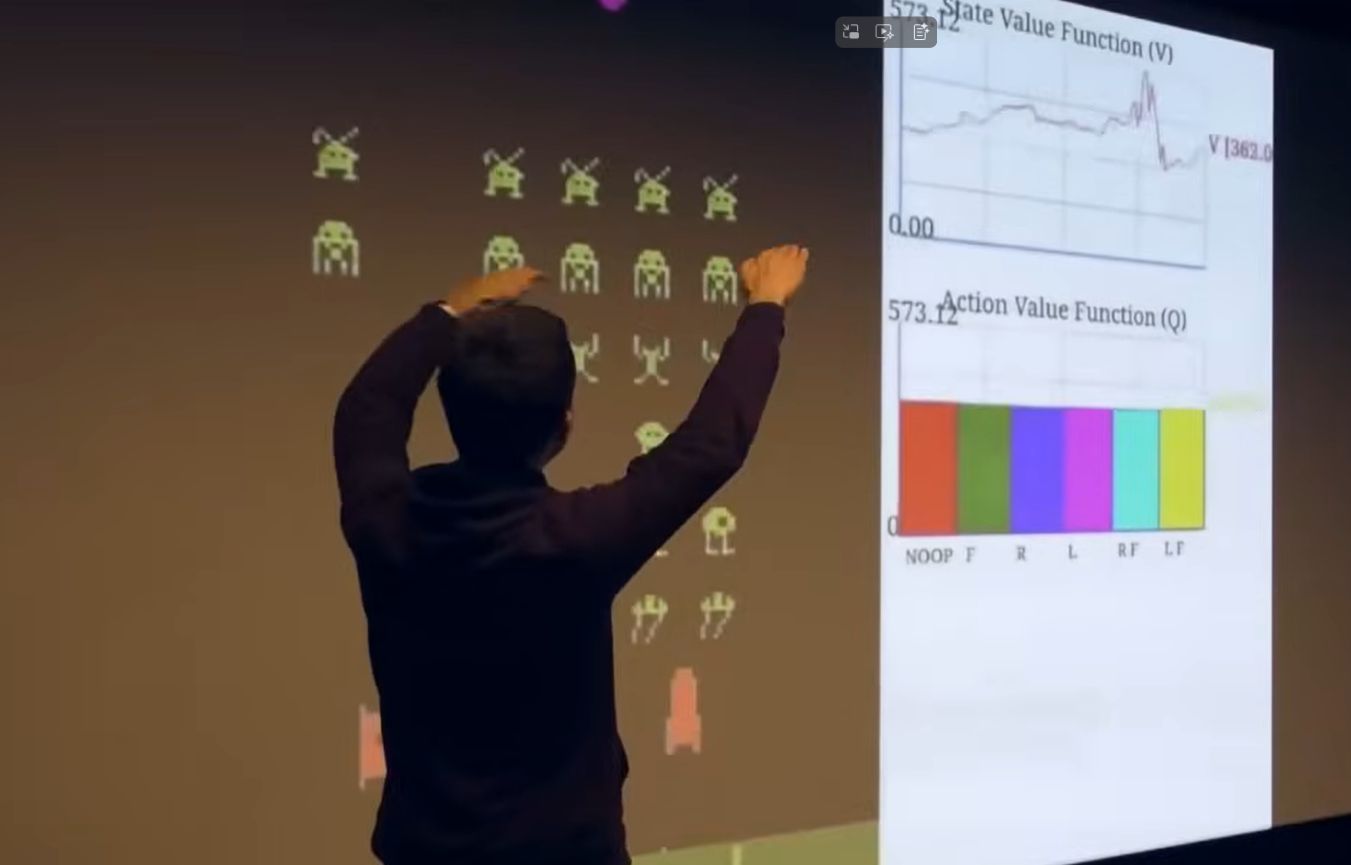
보상 진동(oscillation). 예를 들면 공이 목표물에 가까워지면 보상을 많이 받을것 같으므로 V가 커진다. Space Invaders에서는 mothership이 출현하면 V가 커지지만 놓치면 줄어든다
- Model: 에이전트가 환경을 어떻게 생각하는지
- environment가 다음에 어떻게 행동할지 예측
- Transitions 모델: $\mathcal{P}$ 다음 상태를 예측 (동역학, 헬리콥터가 다음 상태에 어떻게 될 것인지)
- Rewards 모델: $\mathcal{R}$ 다음 보상을 예측
- $\mathcal{P}^a_{ss’} = \mathbb{P}[S_{t+1} = s’ \mid S_t = s, A_t = a]$ 이전 상태를 기준으로 다음 상태에 있을 확률
- $\mathcal{R}^a_s = \mathbb{E}[R_{t+1} \mid S_t = s, A_t = a]$
- not necessary
미로 예시
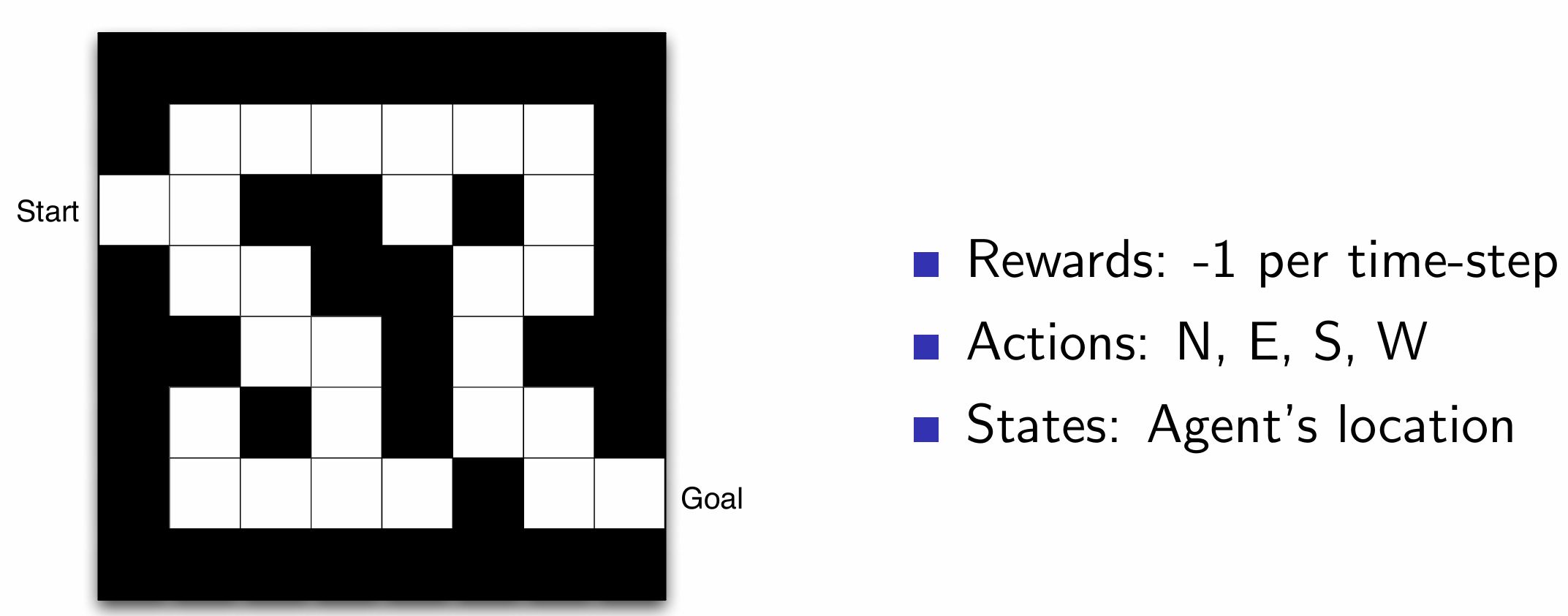
시간에 따라 -1의 보상을 줌으로써 최단 시간에 도착하게 함
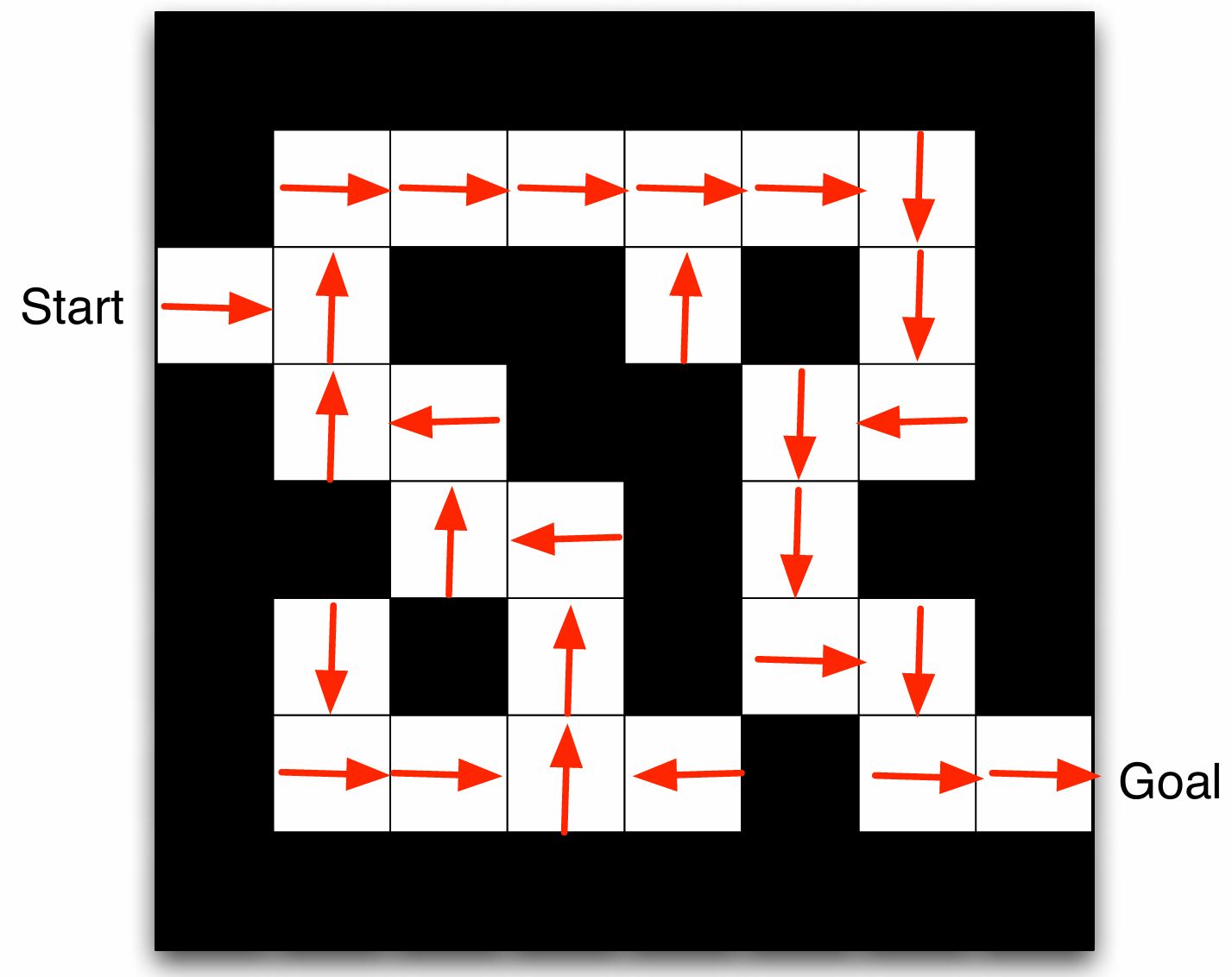
화살표는 state $s$에서의 policy $\pi(s)$

value function: 각 숫자는 상태 $s$에서의 가치 $v_{\pi}(s)$를 나타낸다.

Grid layout은 transition model $\mathcal{P}^a_{ss’}$ 숫자는 state $s$ 에서의 즉각적인 보상 $\mathcal{R}^a_{s}$
- Categorizing RL agents(1)
에이전트에 어떤 핵심 구성 요소가 포함되는지로 강화학습을 분류할 수 있는 분류체계(taxonomy)를 구축할 수 있다.
- Value based: 가치 기반 에이전트. 앞선 예제에서는 value function만 포함하고 있으므로 value가 높은 쪽으로만 greedy하게 가면 되므로 implicit한 policy 혹은 no policy라 부른다.
- Policy Based: 정책 기반 에이전트. 행동에 따라 보상이 달라지는 방식. 명시적으로 value function을 저장하지 않고 가능한 최대 보상을 얻기 위해 공간을 탐색. no value function
-
Actor Critic: 두 가지 장점을 모두 활용하려고 함
- Categorizing RL agents(2)
모델 관점으로도 분류 체계를 구축할 수 있다.
- Model Free: 환경을 명시적으로 이해하려 하지 않음. 헬리콥터 예제에서 동역학을 이해하려 하는 것이 아닌 움직였을 때의 상태와 가치만 보는 경우
- Model Based: 첫번째 에피소드에서 환경이 어떻게 작동하지는지에 대한 모델을 구축. 헬리콥터의 역학 모델을 구축하여 미래를 예측하여 최적의 행동 방식을 파악
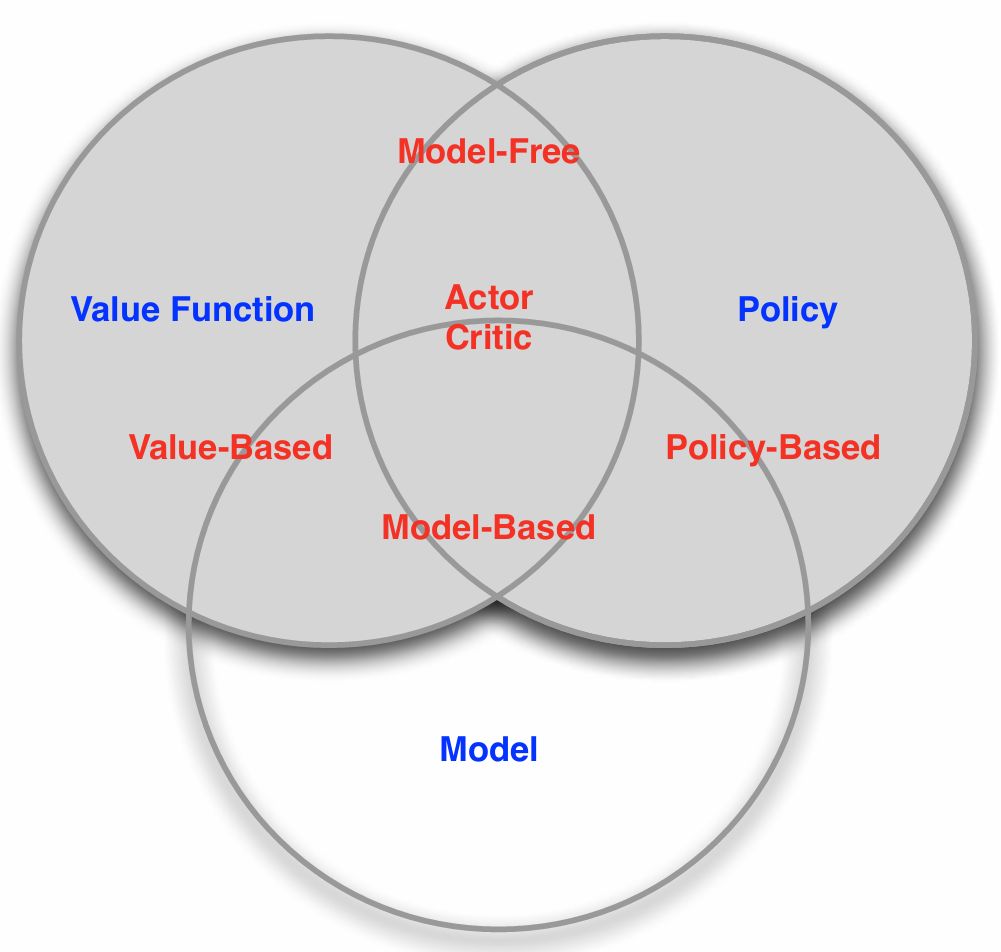
가치함수, 정책, 모델이 있든 없든 행동을 선택해야 함
Two fundamental problems in sequential decision making
- Reinforcement learnig problem
- 환경에 대한 정보가 전혀 없는 경우 (ex 공장에 로봇을 던져놓고 보상을 최대화)
- 에이전트가 환경과 상호작용하고 정책을 개선
- Planning problem
- 환경에 대한 모델을 제공
- 환경과 상호작용하는 대신 내부 모델을 연산으로 연산하여 정책을 개선
Exploration and Exploitation (탐색과 활용)
- 강화학습은 일종의 trial-and-error 학습이다
- 탐색과 활용 사이의 균형을 맞춰야 한다.
- 알고있는 보상을 포기하고 새로운 방향으로 나아감
- ex) 레스토랑 선택(잘 아는 레스토랑/새 레스토랑), 온라인 배너 광고(구글 애드센스, 사람들이 많이 클릭하는 광고 보여주기/새로운 광고 보여주기)
Prediction and Control (예측, 제어)
- Prediction: 현재 정책을 따랐을 때 얼마나 잘 할 수 있는가
- Control: 미래를 optimize
Reference
https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
댓글남기기